Напредване на NLP с ефективни архитектури на модели, базирани на проекция
Дълбоките невронни мрежи радикално трансформират обработката на естествения език (NLP) през последното десетилетие, главно чрез прилагането им в центрове за данни, използващи специализиран хардуер. Проблеми като запазване на поверителността на потребителите, елиминиране на латентността на мрежата, активиране на офлайн функционалност и намаляване на оперативните разходи ускориха развитието на NLP модели, които могат да се изпълняват на устройство, а не в центрове за данни. И все пак мобилните устройства имат ограничена памет и процесорна мощ, което изисква работещите на тях модели да бъдат малки и ефективни – без да се нарушава качеството.
Миналата година Google публикува невронна архитектура, наречена PRADO, която по това време постигна най-модерно изпълнение по много проблеми с класификацията на текст, използвайки модел с параметри под 200K. Докато повечето модели използват фиксиран брой параметри на маркер, моделът PRADO използва мрежова структура, която изисква изключително малко параметри, за да научи най-подходящите или полезни маркери за задачата.
Днес се представя ново разширение на модела, наречено pQRNN, което подобрява състоянието на техниката за изпълнение на NLP с минимален размер на модела. Новостта на pQRNN е в начина, по който съчетава проста операция на проекция с квази-RNN кодер за бърза, паралелна обработка. Моделът pQRNN е в състояние да постигне ниво на BERT при задача за класификация на текст с много по-малък брой параметри.
Какво кара PRADO да работи?
Когато е разработен преди година, PRADO е използвал специфични знания за NLP за сегментиране на текст, за да намали размера на модела и да подобри производителността. Обикновено въвеждането на текст в модели на NLP първо се обработва във форма, която е подходяща за невронната мрежа, чрез сегментиране на текст на парчета (tokens), които съответстват на стойности в предварително дефиниран универсален речник (списък на всички възможни tokens).
След това невронната мрежа идентифицира уникално всеки сегмент, използвайки обучен вектор на параметри, който съдържа embedding таблица. Начинът, по който текстът е сегментиран, оказва значително влияние върху производителността, размера и латентността на модела. Фигурата по-долу показва спектъра от подходи, използвани от NLP общността и техните плюсове и минуси.
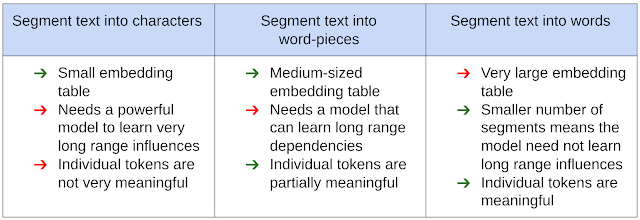
Тъй като броят на текстовите сегменти е толкова важен параметър за производителността и компресията на модела, той повдига въпроса дали един NLP модел трябва да може да идентифицира ясно всеки възможен текстов сегмент. За да отговорим на този въпрос, Google разглеждаме присъщата сложност на NLP задачите.
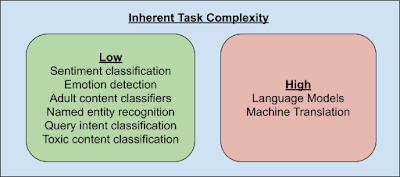
Само няколко NLP задачи (например езикови модели и машинен превод) трябва да знаят фини разлики между текстовите сегменти и по този начин трябва да могат да идентифицират уникално всички възможни текстови сегменти. За разлика от тях, по-голямата част от другите задачи могат да бъдат решени чрез познаване на малка подгрупа от тези сегменти. Освен това тази подгрупа от сегменти, свързани със задачата, вероятно няма да бъде най-честата, тъй като значителна част от сегментите несъмнено ще бъдат посветени на граматичните членове като a, an, the и т.н., които за много задачи не са непременно критични.
Следователно, позволяването на мрежата да определи най-подходящите сегменти за дадена задача води до по-добра производителност. Освен това мрежата не трябва да може да идентифицира уникално тези сегменти, а само трябва да разпознава клъстери от текстови сегменти. Например, класификаторът на сентимент просто трябва да знае клъстерите на сегменти, които са силно свързани със сентимента в текста.
Използвайки тези прозрения, PRADO е проектиран да научи клъстери от текстови сегменти от думи, а не от парчета от думи или знаци, което му е позволило да постигне добра производителност при NLP задачи с ниска сложност. Тъй като словните единици са по-смислени и въпреки това най-подходящите думи за повечето задачи са сравнително малки, са необходими много по-малко параметри на модела, за да се научи такова намалено подмножество на съответните клъстери от думи.
Подобряване на PRADO
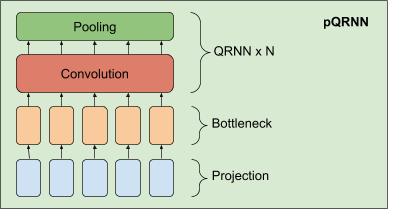
Въз основа на успеха на PRADO, Google разработихa подобрен NLP модел, наречен pQRNN. Този модел е съставен от три градивни блока, проекционен оператор, който преобразува tokens в текст в последователност от тройни вектори, dense bottleneck layer и куп QRNN кодери.
Изпълнението на прожекционния слой в pQRNN е идентично с това, използвано в PRADO и помага на модела да научи най-подходящите tokens без фиксиран набор от параметри за тяхното дефиниране. Първо отбелязва tokens в текста и го преобразува във векторен троен елемент с помощта на проста функция за картографиране. Това води до тройна векторна последователност с балансирано симетрично разпределение, която уникално представлява текста.
Това представяне не е 100% полезно, тъй като не разполага с информация, необходима за решаване на интересуващата задача и мрежата няма контрол върху това представяне. Google го комбинират с dense bottleneck layer, за да позволим на мрежата да научи представяне на дума, което е от значение за съответната задача.
Представянето в резултат на dense bottleneck layer-а все още не взема предвид контекста на думата. Научаваме контекстуално представяне, като използваме куп двупосочни QRNN кодери. Резултатът е мрежа, която е способна да научи контекстно представяне само от въвеждане на текст, без да използва каквато и да е предварителна обработка.
Производителност
Google експертите оценяват pQRNN на набора от данни civil_comments и го сравняват с модела BERT за същата задача. Просто защото размерът на модела е пропорционален на броя на параметрите, pQRNN е много по-малък от BERT. Но освен това pQRNN се квантува, като допълнително намалява размера на модела с фактор 4x.
Публичната предварително обучена версия на BERT се представя слабо със задачата, поради което сравнението се извършва с версия на BERT, която е предварително обучена на няколко различни релевантни многоезични източника на данни, за да се постигне възможно най-доброто представяне.
 |
| Захващаме площта под кривата (AUC) за двата модела. Без каквато и да е предварителна подготовка и току-що обучена по наблюдаваните данни, AUC за pQRNN е 0,963, използвайки 1,3 милиона квантовани (8-битови) параметри. С предварително обучение за няколко различни източника на данни и фина настройка на контролираните данни, моделът BERT получава 0,976 AUC, използвайки 110 милиона параметри с плаваща запетая.Conclusion |
Използвайки моделът PRADO от предишно поколение, Гугъл експертите демонстрират как той може да се използва като основа за следващото поколение модерни модели за класификация на леки текстове. Представя се един такъв модел, pQRNN, и се показва, че тази нова архитектура може почти да постигне производителност на ниво BERT, въпреки че е 300 пъти по-малка и е обучена само на контролирани данни. За да се стимулират по-нататъшни изследвания в тази област, Гугъл отварят модела PRADO и насърчават общността да го използва като отправна точка за нови архитектури на модели.





