Обзор на Google – Април 2021

Google Search – По-критичeн за сайтовете за електронна търговия, които продават медицинско оборудване
Джон Мюлер от Google заяви, че “особено за медицински теми, Google е по-селективен и критичен”. Той каза, че в това число попада и „сайт за медицинска електронна търговия я“. Накратко, Google ще прилага по-високо ниво на контрол върху сайтове с медицинска информация, включително сайтове за електронна търговия, които продават медицинско оборудване, когато решава къде да класира този сайт. Нуждаете се от повече сигнали на E-A-T, когато се опитвате да класирате по медицински въпроси – било то информационни или транзакционни.
Google: Staging сайтовете трябва да използват потребителско име и парола, за да блокират индексирането
Джон Мюлер от Google отново заяви, че най-добрият метод да блокираме Google да не обхожда и след това да индексира вашия сайт е да блокира GoogleBot и други хора с удостоверяване / логване. Подканете заявката за достъп до подготвителния сайт, като поискате от тях да въведат валидно потребителско име и парола за достъп до тестинг средата.
Google: Можем да разпознаем и разберем странирането чрез вътрешни връзки
Накратко, Джон каза, че Google вече не използва rel=”prev” / rel=”next” и вече не е необходимо да се имплементират. Google вече е „в състояние да разпознава често срещаните типове настройки за разбиване на страници“, каза той.
Джон добави, че някога Google ги е използвал, за да разбере страницирането, но сега Google е „в състояние да разпознава често срещаните типове настройки за разбиване на страници“, каза той. Той добави, че Google „може да ги обработва като нормални вътрешни връзки и да разбира контекста оттам“, добавяйки, че Google „вече не се нуждае от тези специални атрибути на връзките“.

Защо Google често третира 302 пренасочвания като 301 пренасочвания
Джон Мюлер от Google много пъти е казвал, че 302s срещу 301s са почти едно и също по отношение на това как Google третира пренасочванията. Той често казваше – не се притеснявайте да използвате 302 над 301 или обратното. Въпросът е защо? Джон основно каза, че по-голямата част от мрежата използва едно и също, така че Google използва множество сигнали, за да определи колко често е използването на пренасочване от вид 302 или не.
Ако Google види пренасочване 302 на място в продължение на няколко месеца, бихме предположили, че Google ще промени състоянието на “временното” значение на пренасочване на код на състоянието 302 и ще го третира по-скоро като пренасочване 301, което е “постоянно” пренасочване.
Какво означава това технически за Google? Джон Мюлер обясни в Twitter и както обяснихме тук по-рано, “с пренасочвания, ние сме склонни да поставяме URL адреси в една и същ “контейнер” и след това да използваме канонизация, за да изберем кой да се покаже”, каза Джон. “Класирането обикновено ще бъде еднакво, така че дали това е източник или целеви URL адрес, всъщност няма значение”, добави той. ”
“Временното пренасочване (като 302) е по-скоро да ни каже, че URL адресът на източника може да бъде предпочитан, докато постоянният предполага, че целевият URL адрес ще бъде. Използваме много повече от просто пренасочвания за канонизация. Това е обикновено защо 302” предпочитан от източника “в крайна сметка се третира по-скоро като 301„ предпочитан от дестинацията “с течение на времето. Например, ако всички външни и вътрешни връзки сочат към дестинацията, вероятно трябва да изберем и дестинацията. Няма фиксирано време за прекъсване за че.”
С течение на времето Google трябва просто да го разбере. Повечето разработчици не се замислят как Google вижда пренасочване 301 срещу 302, това е факт. Така че Google знае това и се справя с това.

При миниизображението на Google Video Structured Data Url добавя поддръжка за WebP и SVG
Google направи малка актуализация на помощните документи за структурирани данни за видео, за да съобщи, че thumbnailUrl вече поддържа и WebP и SVG формати на изображения, в допълнение към вече документираните формати на изображения BMP, GIF, JPEG и PNG.
Google пише, че на 7 април 2021 г. „актуализира документацията за структурирани данни за видео, за да заяви, че свойството thumbnailUrl може да използва един от поддържаните файлови формати на Google Images. Преди това документацията не включваше WebP и SVG“.
Googlebot не оценява основните Core Web Vitals – Chrome го прави
Джон Мюлер от Google посочи важен факт, че вижда неразбирането в бранша около основните Core Web Vitals метрики. Googlebot обхожда мрежата и внася повечето от сигналите, които Google използва за класиране на вашите страници, но основните Core Web Vitals не идват от Googlebot или обхождането, а от отчета за данни на Chrome CRuX.
Това означава, че Google използва реални данни за използването на Chrome, за да въведе данни около Core Web Vitals за конкретни страници. Това включва резултатите LCP, FID и CLS. Обхождането на Googlebot не е източникът, от който Google получава тези данни. Използването на Chrome, човек, който посещава вашия сайт в браузър Chrome, е мястото, от което Google получава тези данни.

Google за това как разпознава автори без авторство
Джон Мюлер от Google описа как Google е в състояние да разпознае автор и цялото му съдържание и споменавания в мрежата, без вече да поддържа маркиране на авторството. Накратко, Джон каза, че Google може да направи това, когато всички статии на автора водят обратно към централна био страница или централно местоположение.
Джон беше попитан: “Каква информация за контакт е по-добре да се посочи на страницата на авторите, акаунтите в социалните мрежи, имейл адресите или и двете? Ако можем да изберем само една опция, каква е по-предпочитано? “
Джон каза: “нашите системи се опитват да разпознаят кой е това, което е това лице. И ние го правим въз основа на редица различни фактори и това включва неща като връзки към страници на профила например. Или видима информация, която можем да намерим на тези страници. “
Тогава Джон каза, че неговата препоръка тук би била „да се свърже с общо или нещо като централно място, където казвате, че всичко се събира за този автор, което може да бъде нещо като страница на профила в социалната мрежа например“. След това Джон добави, че можете да „използвате това в различните авторски страници, които имате, когато пишете, така че когато нашите системи разгледат дадена статия и те видят авторска страница, свързана с това, те могат да разпознаят, че това е същият автор като човекът, който е написал нещо друго и ние можем да групираме това по обект и го правим въз основа на може би този общ профил в социалната мрежа, който е там. “ Google тук изгражда цялостно разбиране за автора въз основа на връзките от авторските статии.
Google: Поставянето на breadcrumbs не е от значение за SEO
Джон Мюлер от Google заяви, че що се отнася до breadcrumbs, връзките, които виждате на страници, които ви казват откъде сте кликнали, разположението и местоположението на тези breadcrumbs всъщност не са от значение за SEO. Джон каза „не, разположението няма значение за SEO“.
„Използваме breadcrumbs за обхождане (намиране на вътрешни връзки) и за богати резултати (структурирани данни); и двете не зависят от разположението на breadcrumbs“, обясни Джон.
Google: Страницата трябва да премине проверки за качество за индексиране
Gary Illyes от Google заяви в Reddit, че за да бъде индексирана страница от Google, „съдържанието трябва да премине проверки на качеството“. Ако това съдържание не премине проверките за качество, Google може да не го индексира, дори ако ръчно се опитате да изпратите страницата на Google за индексиране.
Уеб администратор на Reddit се оплака, че функцията за индексиране на заявките на Google Search Console „не работи“. Така че Гери се намеси, че работи, но дори и да поискате индексирането, Google може да не индексира страницата. Гари обясни: “Имайте предвид, че това не е гаранция. Съдържанието все още трябва да премине проверки за качество, за да бъде избрано за индексиране.”
Затова уебмастъра попита какво може да направи, за да се индексира и Гари каза, фокусирайте се върху подобряването на качеството.
Q&A в Google Официално си отиват, но центърът за въпроси не е засегнат
Вчера Google потвърди с мен, че докато функцията „Въпроси и отговори за Google“ наистина изчезва, Google Question Hub няма да бъде засегната от това. Въпросният център е отделна, но подобна характеристика на тази на Въпросите и отговорите в Google, откъдето идва и объркването.
Google обикновено не спира сайтовете от Google Discover
Пол Бакаус от Google, който днес е силно ангажиран с уеб истории, заяви в Twitter, че в Google „обикновено не„ спираме “сайтовете и когато отстранявате проблеми, винаги имате право да се появявате отново“. Така че, въпреки че може да помисллите, че след актуализация на ядрото на Google вашият сайт е спрян от Google Discover, по-вероятно е вашият сайт да бъде счетен алгоритмично, че не е достатъчно качествен, за да се покаже в Google Discover. Или отговаряте на условията, или не, въпреки че това може да е прекалено опростено как работи.
Google дори актуализира своите помощни документи за Discover, за да добави много подробности около това защо E-A-T е важен за Google Discover.
Google е променил Cumulative Layout Shift
Google направи промени в начина, по който изчислява CLS, метриката кумулативната промяна на оформлението в рамките на Core Web Vitals. Конкретно максимален прозорец на сесията с 1 секунда интервал, ограничен до 5 секунди. Това беше направено, за да стане “по-справедливо за дълго зареждащи страници и приложения за една страница”, каза Малте Убл от Google.
Google: След рендиране – съсредоточете се върху това дали вашият сайт добавя стойност спрямо останалите
Gary Illyes от Google каза, че що се отнася до класирането в Google, често не става въпрос за Core Web Vitals в мрежата, ако използвате AMP, нито за размера на вашата база данни. След като разберете, че Google може да осъществява достъп и да изобразява вашите страници, следващата стъпка е да се уверите, че съдържанието ви добавя стойност над конкуренцията.
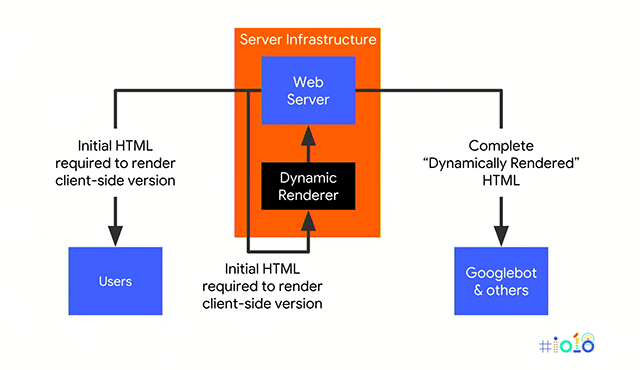
Какво представлява слоят отгоре на услугата за уеб рендиране на Google Търсене
Има една интересна информация, която можете да научите за услугата за уеб рендиране на Google (WRS) в хенгаутът за JavaScript на SEO с Мартин Сплит от Google, където Мартин каза, че има слой върху WRS, който обработва „приоритизиране, повторен опит за грешка, гаранции за качество на услугата, кеширане и също така взаимодейства с подсистема за обхождане, за да извлече действително нещата.“
Хей, Google, трябва ли да оптимизираш целия си уебсайт, за да може една страница да се класира добре?
На Джон Мюлер от Google беше зададен един интересен въпрос – трябва ли да оптимизирате целия си уебсайт, ако се интересувате само от един URL адрес, една страница, на целия този уебсайт, за да се класирате добре?
Джон каза “ние гледаме предимно страницата, когато става въпрос за класиране, но тя винаги е вградена в контекста на целия ви уебсайт.” Той добави „Бих казал, че си струва да подобрите уебсайта си като цяло“, като обясни, че Google „разбира много по-добре как тази страница е наистина важна и каква е стойността на тази конкретна страница“, ако оптимизирате целия сайт, от който е част тя.
По-конкретно Джон обясни „вътрешното свързване и разбиране на заглавията и съдържанието на страниците – всичко това ни помага, дори ако е извън тази страница, която ви интересува“.
Така че Джон каза: „Бих казал, че ако ви е грижа за една конкретна страница на вашия уебсайт, трябва да сте сигурни, че останалата част от уебсайта, който е свързан с тази една страница, също е подобрена, доколкото е възможно“.
Soft 404-ти или Noindex празни страници за Google
Мишел Рейс, известна още като ShelliWeb, зададе интересен SEO въпрос, тя попита какво е по-добре за Google, когато имате празни уеб страници. Трябва ли да ноиндексирате празната уеб страница или да оставите Google да я индексира и да я третира като Soft404?
Конкретният случай е, че създавате страница с категория, но все още нямате продукт на тази страница. Какво правите междувременно, докато чакате продуктите да влязат в тази категория. Ноиндексирате ли го от Google или оставяте Google да индексира празната страница и да я третира като мек 404?
Джон Мюлер от Google каза, че всъщност няма значение. „Не мисля, че ще има забележима разлика между тези два подхода. Когато нещата се променят (празно -> съдържание), обикновено получаваме сигнали от различни места (напр. вътрешни връзки), така че можем да използваме това, за да се активира crawling, когато е необходимо. ”
“Сега, разбира се, може да е най-добре да имате функция, която да не показва страницата изобщо, без да има съдържание върху нея. Не я добавяйте към навигацията си, не я представяйте на потребители или търсачки, докато страницата не съдържа съдържание.” Но в този конкретен случай трябва да има бизнес или техническа причина първо да се показва без съдържание. Така или иначе, отговорът на Джон е интересен и нов.
Google: Отзивите за продукти, генериращи съдържание, ще имат трудности в класирането добре
Джон Мюлер от Google намекна, че тъй като актуализацията на отзивите за продукти е пусната, ще бъде трудно съдържанието публикувано от потребителите, да се класира добре в Google Търсене. Джон заяви в Twitter, че “фокусът там е очевидно върху отзиви от експерти. Поддържането на високо качество на сайта на UGC е трудно, нямам просто решение.”
Джон основно казва, че новият алгоритъм на Google има за цел да класира отзивите за продукти, написани от експерти, хора, които наистина се справят чудесно с прегледа на продукта, по-високо в резултатите от търсенето от други видове отзиви за продукти. Ако случайни хора могат да изпратят някакъв отзив за продукт, който сте изброили на вашия уебсайт, за вас би било много трудно да контролирате качеството на това съдържание и по този начин вероятно няма да се класира добре. Всичко е възможно, но като цяло истинският експерт няма просто да се отбие в някой произволен сайт и да остави супер подробен преглед на продукта за вас.
Google: Разбийте съдържанието на YMYL и Non-YMYL на отделни сайтове
Ако вашият уебсайт съдържа както YMYL, така и не-YMYL теми на съдържанието, може да помислите за разделянето им в техни самостоятелни уебсайтове. Джон Мюлер от Google намекна, че понякога Google може да направи това автоматично, но е по-безопасно да го направите от ваша страна, така че да не се налага да отговаряте на конкретно E-A-T изискване, или праг за не-YMYL съдържание на този сайт.
Джон Мюлер от Google заяви, че „алгоритмите на Google винаги ще имат предизвикателството да разберат как да се справят с този уебсайт. Така че независимо от каквото и да било около YMYL или EAT , ако имате тази комбинация от много полярни противоположности почти по отношение на съдържанието , тогава бих предположил, че алгоритмите на Google винаги ще се борят да измислят как да класират уебсайта. “
