Make your website easier to be crawled by Googlebot

Webinar sum up : Make your website easier to be crawled by a Google bot with Murat Yatagan
28.02.2019 Borislav Arapchev
The webinar that took place on 26th of February 2019 organized by SEO agency Serpact about the topic „Make your website easier to be crawled by Googlebot“ with Murat Yatagan was very useful and rich in practical information. Today we present you Murat Yatagan and the interview with him.
You can watch the full webinar here:
https://www.youtube.com/watch?v=LTrT0DszxWo
Murat Yatagan is an SEO consultant with more than 8 years of experience in SEO and UX, five of which in the position of senior analyst of products for the Google’s search team in Ireland.
Murat has been part of several Google teams such as control for web spam by a specific approach to manual actions , review requests, websites recovery, link profile analysis and community management. Since 2018 Murat has been working for Brainly as a vice president of the growth in Poland. Murat works also as a judge in US, UK, EU & MENA Search Awards.
We continue with our conversation
Dido: Hello, Murat! It’s an honor for us to have you today. Please, tell us about yourself, how did you achieve to integrate in this sphere, to be in Google, etc.?
Murat : I was in university and was doing a research when I was working on my master’s degree as a research assistant and a job related to neural networks. I always wanted to continue my education and study doctor’s degree on this subject. Then I went in Dublin, Ireland for 2 weeks as an exchange student. I realized there are several companies there and decided that I can apply for a job to one of them. And Google was the best possible offer. And then I started my job in the Web Spam team which is also known as Search Quality /now it’s called Trust and Safety/. Being a product top analyst I was trying to find Web Spam problems in Google’s index, in the different languages. After 5 years I decided to take up the challenge for myself and start my own business. So I returned to Turkey. There I gathered a team and started consulting different clients in the sphere of SEO, clients from USA, England, Germany, Poland, Turkey, Australia. Some of them were really big companies but I can’t mention them because we have NDA, and the other ones were small starting businesses. Afterwards I decided to turn back to Europe and for 6 months I have already been working in Brainly. In Brainly we already have 150 million unique users monthly, we manage more than 10 domains and we serve 25 different languages.
Dido : What was the biggest challenge for you when you was working in Google? Was it your everyday job or something more special in your career there?
Murat: The biggest challenge and the thing that was most satisfying was that I worked with very smart people, extremely smart minds who were also hardworking people in the same time. The competition in the team was big, but everyone was doing the job they can do best. The atmosphere was unique and it was a place where you learn something new everyday. My job there was never a routine and can’t be described as boring. It was rather inspiring and challenging, full of unique ideas everyday.
Dido: So your job at Google is creative and stimulates you to have new ideas and develop?
Murat: Absolutely. For example, my manager said to me that I can use 20% of my time to decide what I can work on. I decided to work with different teams on different projects. 20% is not little and this means in one day of the week you work on something different.There is something really interesting when hiring people in Google. There is the question what they will do if they have free time – watch YouTube videos or work on a problem that needs a solution.
Dido: It is great that Google allows freedom for development and encourages the ideas of the people working in the team.
Murat: That’s right. But this doesn’t mean that you can show an idea and they will tell you – ok, let’s do this. You have to first offer data, to defend your idea and its sense and usefulness. Then the idea it’s applied in a starting stage, lightweight. When the idea is developed and it’s obvious that it brings results, the team can start using it on a deeper level and hire a separate team for this job.
Dido : Our topic today is Crawl budget, and you told us that you have prepared a presentation, so we are anticipating it with excitement. We will be happy if you share with us your knowledge and probably some secret. If you have any questions, tell them to us so we can ask Murat about them.
Murat : Let me share with you my screen. Today we are going to talk about how you can make your webpage easily crawlable by search engines bots, and especially by a Google bot, about which I have the most knowledge.
Here is the content for today:
1.The life of an URL
- What is a crawl budget?
- Important factors that influence the crawling process
- Domain build up
The life of an URL
The life of an URL means its path from the moment when it’s published on the web to the moment when the search engines engage with it in a certain way.
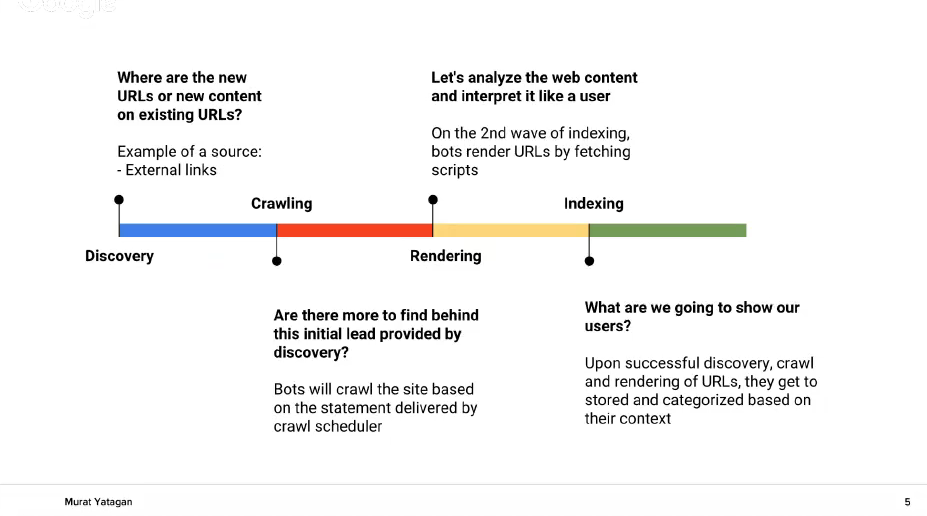
А. The first step is finding the web address /Discovery/. You know that one of the functions of Google is to organize the web. In this way by crawling of old and already known addresses of Google, the search engine can find new addresses. But according to a different meta data and parameters, such as the old PageRank for example, Google determines which addresses to crawl first. Google also determines the number of addresses that should be crawled for a certain site.
- B. In this way the process passes to the stage /crawling/. The crawling is done by a Google bot. The bot decides if there are other addresses behind the recently found The bot also determines the crawling frequency. On this stage the Google’s bot analyzes HTML sitemaps and the internal links to find new addresses.
- C. The third stage of the process is /rendering/. Then Google fulfills the scripts in the page and „views“ it as a user. The purpose is to understand the context of the page.
- D. The fourth and last stage of the process is /indexing/ – in other words– submitting and categorizing the webpage according to its content and context. Google saves tons of data for every webpage in order to categorize it. Afterwards the address is send to the ranking algorithm so that the address is classified according to its own parameters. The magic happens exactly with the algorithm.
Dido: Quick question about the Discovery stage. There are many speculations circulating the web that state finding new addresses is realized by a machine learning algorithm. Is this true?
Murat: Yes, machine learning is in fact a technique that teaches itself. And it can be used for many processes. So this is possible.
The concept behind Crawling
We have information what addresses can and cannot be crawled. It’s certain that the Google bot respects and follows the instructions of the robots.txt file. So if you want a certain web address to be crawled you shouldn’t add it to sitemap and also limit the bots’ access to it – with a password or other limitation. Google’s bot crawls the publicly available URL addresses, from page to page, from link to link and it crawls the content in this way. Then it sends it to Google data centers.

Google has to plan how many addresses it has to crawl per day and how often it should visit the website because in fact traffic is paid and the hosting is loaded.
What is Crawl Budget?
One of the factors that determine crawl budget is the page’s authority. The crawling starts from the page with the highest PageRank. We know how much is PageRank. It’s a very complex algorithm. But we can determine it relatively when we know which page is more important, check our log files and also by knowing that home page is crawled more often than the other pages. This is normal because all other pages have links to the main page. Usually users visit home page most often. Even if they come upon an internal page with a search engine, they almost always visit the home page as well. Besides crawling process doesn’t work accidentally. It usually starts crawling the first fresh content.
Definitions and parameters

Every visit by a bot of a page has a value and it loads the server of the domain it visits. That is why visit limitations like quota are introduced. Also crawl schedulers determine how many URLs from a certain domain will be crawled for a certain amount of time. This plan in SEO industry is called crawl budget. It’s not static and cannot be changed. If your hosting reacts fast then Google’s bot can crawl 1000 URLs for 10 min. The bot sets itself a frame for example: I will crawl 1000 URLs form this site but I cannot spend more than one hour. If you web pages don’t load quickly, the bot may not be able to crawl these 1000 addresses and will give up somewhere reaching its time limit. Here we are talking specifically about crawl optimization – you have to make sure that your new content and your most important pages will be easily and quickly crawlable by a Google bot.
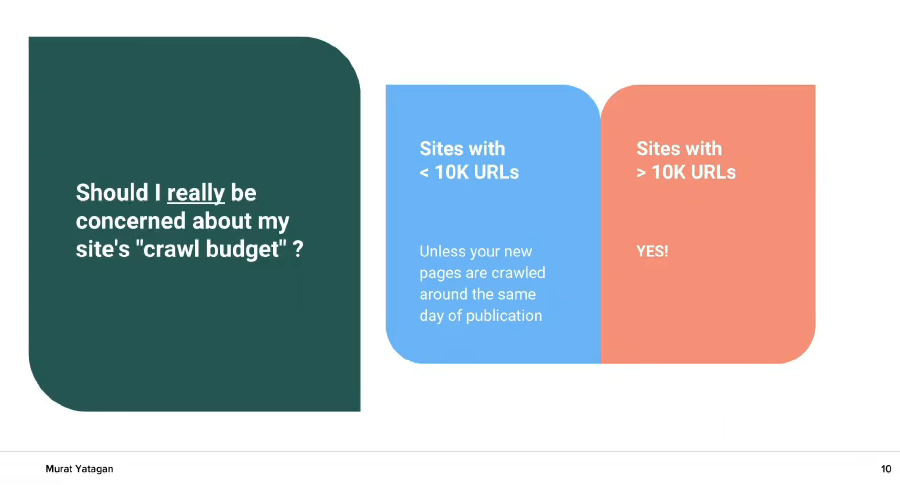
Should you worry about your crawl budget? If your site has less than 10 000 URLs – usually not. If there are more than 10 000 URLs – the answer is yes! If your website has 1 million URLs or more, crawl budget should be your top priority.
Important factors that influence crawling
Let’s focus on those 5 factors because they are very important and cover the process of /crawling/.

- Capacity to respond quickly
If you hosting responds quickly to Google bot’s requests, there is high chance that the craw rate of these requests will increase and also a Google’s bot visit will last fast. In this case you can improve Time to last byte /TTLB/ and the usual time it takes for the bot to load an URL page.
- Domain health
If your site have a lot of mistakes from the type 50x, 40x, soft 404 and they increase – be careful. If you have many redirect chains, broken redirects, misuse of robots.txt and sitemap.xml – these are factors that influence the “health“ of your domain and the crawling of your site by the search engines bots.
- Quality of pages
If you decrease the number of pages with little or missing content, this will bring you benefits- better crawling of your site by the bots. Strive to maintain a content at a high level on your website. That’s because when a Google bot crawl your site and find many pages with missing or low quality content it will tell itself : „This site is consists mainly of pages with low quality content, why should I crawl it so often?!“. Therefore the bot decreases the crawling frequency for this site.
Dido: Murat, quick question– there is a lot of duplicated content on the sites of online stores related to products, categories ,etc. There is a way to correct this, of course, but is it a problem?
Murat : Yes, it’s normal to have duplicated content in the case of online stores. But you should work for its improvement – with a canonical tag, or correction of the site’s architecture. Also, if you have internal search in the website or a filter with 50 different parameters that generate duplicated pages- remove them from the indexing. They are not needed by Google.
Nikola: Do you recommend the combination of different versions of particular product, such as color or size, in a product rather than combining different products with these versions?
Murat: You have to analyze what is the search frequency of these products. If you have a big search rate, for example, like Nike Blue /searches/or Nike Red /5 000 searches/ – then make pages about them, because it makes sense. Think about how the user might feel when he comes upon these pages.
- Internal linking structure
It’s a really important point. In this case you have to think about your structure and pages– at what distance they are located, how many clicks are needed to reach them. If they are located at a deep level, they are difficult for finding and this is bad. They won’t be reached by the user nor will they be crawled by a Google bot. They will also not receive Pagerank value. Then think about correction of your website’s structure or other methods that will show this content at front position.
- Freshness
In the case of fresh content make sure it’s visible and can be crawled quickly and easily by Google, because users search new content and Google prefers it. New content gives authority to the brand because when I have new information on a certain topic I am more informed and make better and more actual conclusions. Also PageRank decreases with time and we have to „maintain“ with new /fresh/ content.
Nikola: Murat, one question from our audience, why TTLB /Time to last byte/, but not TTFB /Time to first byte/, and what’s your opinion about FCL /First Content Load/?
Murat: TTFB is important and it shows when Google starts loading a page. FCL and TTFB are equivalental. But to determine Page Score of the page , Google has to crawl it, pass through the whole page /using the technique Lighthouse/, and then show TTLB. TTLB is important.
Capacity to respond quickly – page speed optimization
This is a case of a client that came for help. He has a low crawl rate and when they came to us, the crawl rate of their pages was really low – around 1000 milliseconds.
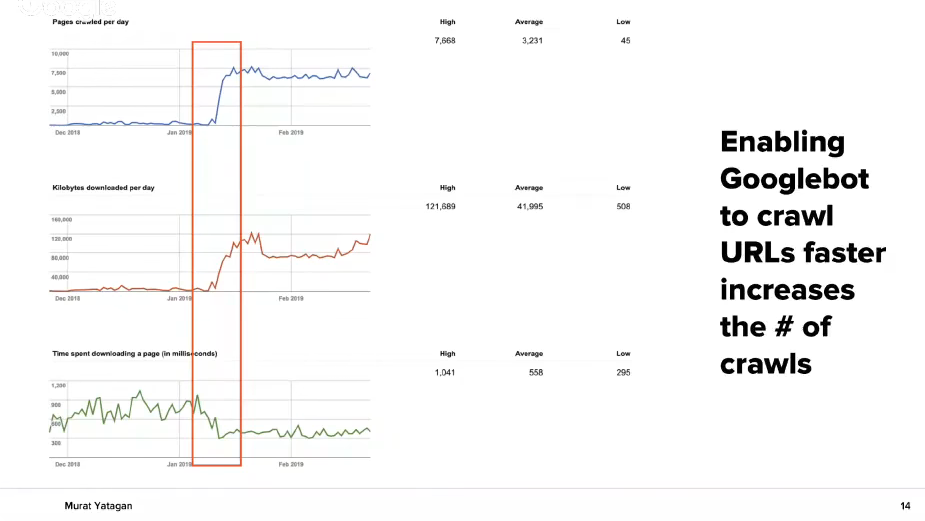
We improved its speed /page speed optimization and internal links improvement/and activated for crawling by Google bot. After this the crawling of the website will increase several times as you can see on the graph. Small steps but with a big effect.
The same goes for load time. No matter how fast speed you achieve, the more often Google will crawl your website. But this will also positively influence your ranking in SERP.
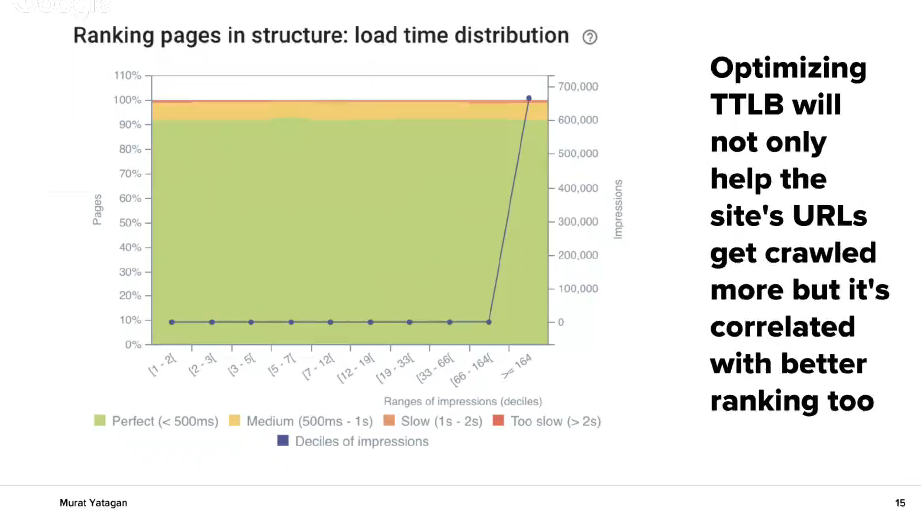
The better speed you achieve, the better and more accurate Google will crawl your website.
Domain health – site sanity exploration
The graph below shows visibility : the increase of 4xx and 5xx leads to a decrease in the frequency of website crawling by a Google bot.The correction of these mistakes turns back the previous good metrics.
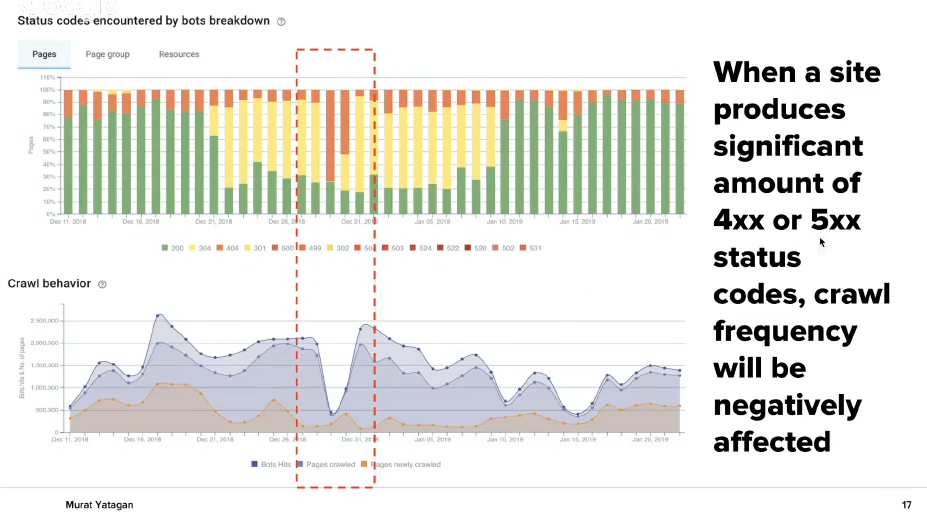
The graph below shows the dependence: the increase of 4xx и 5xx mistakes leads to decrease in the frequency of website crawling by Google bot.
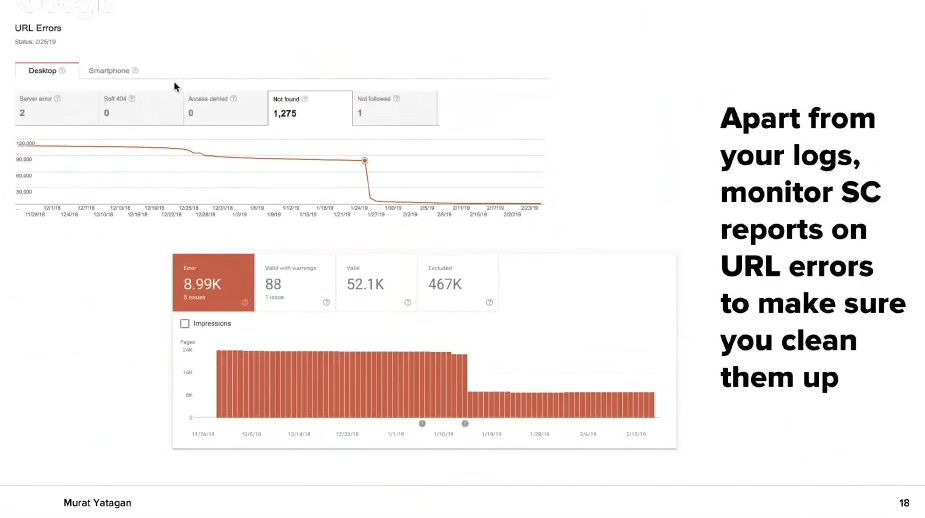
Also, check regularly the URL mistakes in Google Search Console. If you have problems there, work on their solution as it is shown on the picture to decrease them or remove them completely.
Quality of pages – Quantify the quality
Quality is something that cannot be measured. The next graph shows you the connection the pages have positioned in top 1-3 with their load time and their average number of words.
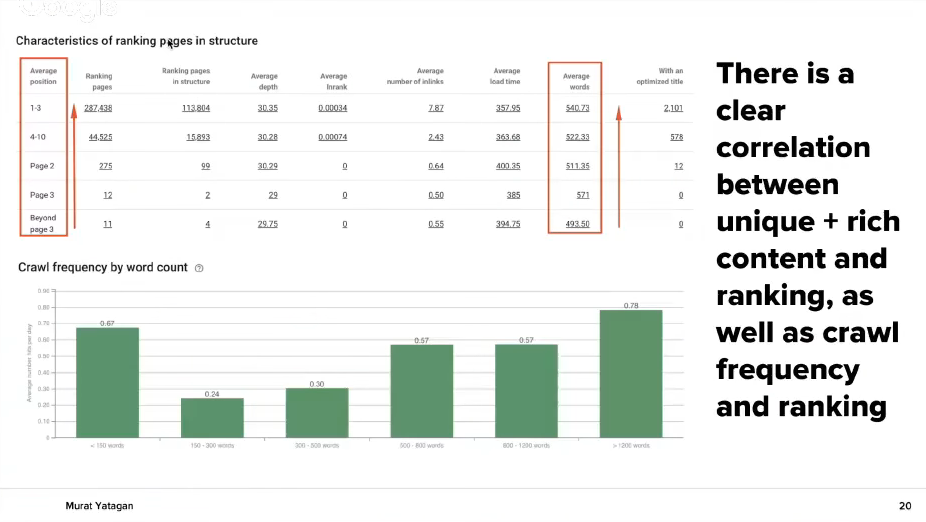
There is a direct link between unique, rich content and ranking. Also there is a link between crawling frequency and ranking. Remove duplicated content on your website. This will make your important website pages be crawled more often.
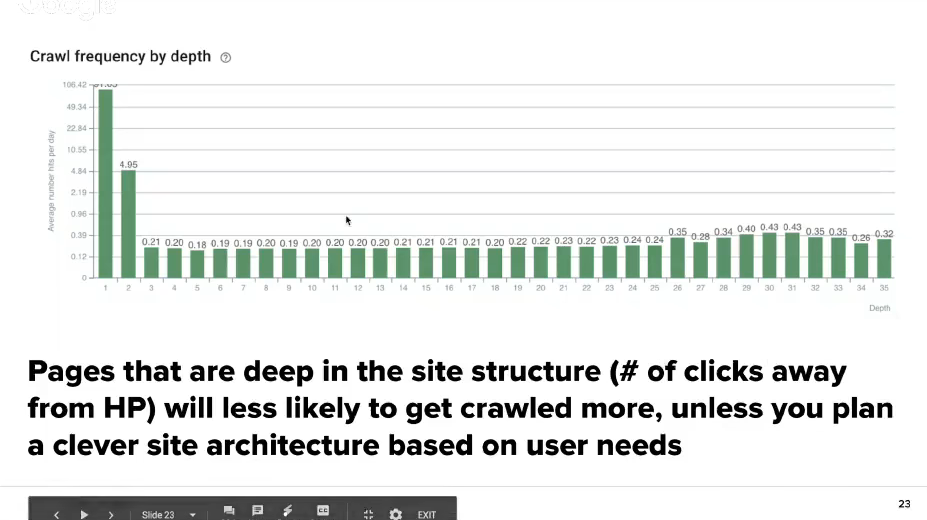
Internal linking structure – PageRank propagation
This graph shows the crawling frequency according to the depth of the URL address on the website. The pages that are deeper located in the structure of the website and are far from the home page will be crawled less. Therefore you have to change the website’s architecture according to the client’s needs. When you have a website with a deeper structure, categories, subcategories, it’s more difficult for these pages to be shown to the bot. That’s why we have different methods like Google crawling tags.
PageRank weakens with time if there isn’t new content or activity. Also Google continues searching for new pages or added new content to already existing old pages. Therefore you should maintain your website up-to-date and fresh and post often on it.
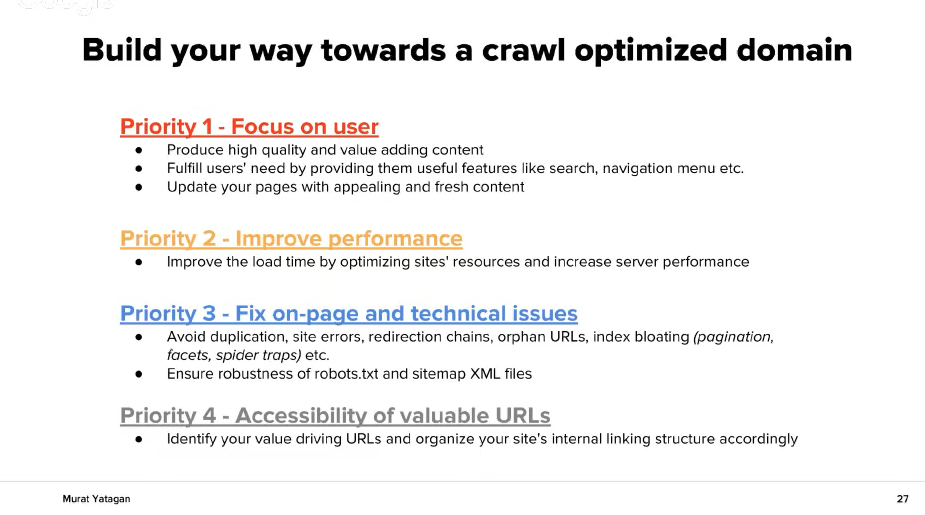
Tips for crawl optimized domain
Priority N 1 – Focus on the user:
new, quality content that gives value
meet the needs of the client
add new content to your pages
Priority N 2 – Improve performance:
Improve load time with corrections to the website’s resources and the server’s
Priority N 3 – Resolve on-page and technical problems:
Avoid duplicated content, redirection chains, orphan URLs, etc.
Test robots.txt and sitemap.xml to check if they are working properly
Priority N 4 –Accessibility to the valuable URL addresses.
Evaluate your most important URL addresses and organize your website’s structure so that it revolves around them.
Thank you!!!
From the audience: What can we do with 10 million URLs in our site map and how to prioritize them – according to keyword volume or other parameter?
Murat: You should arrange your addresses by age, publishing date. For example –map for January, map for February, etc. By doing this you can reach 50 site maps for example. In this way you can achieve an indexing ratio for every package with addresses. But you should also categorize your website /by context and value/, and by the website’s site maps.
Nikola: What do you think about the future of SEO? Should we expect some surprising changes or not?
Murat: Besides 10 results, Google started showing more often featured snippets. Alexa Echo, Google Home and other has already entered the SEO sphere and they are changing the rules. Many people use informational searches, some use transactional. The first thing to be done is to understand the purpose of a given search.
I think that after you started searching something in the search engine, the following happens. If you are searching for recipes, you will receive featured snippets. If you are searching for song lyrics, you will receive featured snippets. If you are searching for airplane tickets and where you can make a booking, you will get featured snippets. This changes the SERP. Google understands in better way what do you want and gives you the desired result.
PDF: How to create crawl optimized domains. – Copyrights (c) https://muratyatagan.com





