What is Latent Semantic Indexing?

Latent semantic indexing has a great impact today in optimizing websites. It “transforms” the content so that it looks written for users, not just search engines. LSI itself is a mathematical model that aims to establish and “understand” the bonds between keywords, ideas and concepts.
When search engines crawl the pages of a website, they look around and collect the most commonly used words and phrases to identify the keywords for the particular page. When analyzing the page using this method, stop words such as prepositions and alliances are not taken into account. In addition, LSI searches for words that are used in the same context because it is believed that they will have a similar meaning or specific connection to each other.
Example: If you are looking for information about a famous person such as Roger Federer, you will find a wealth of information about tennis tournaments that does not even mention his name! Thus, search engines, using LSI, provide the user with relevant search query information, without necessarily having this request included in the information.
How does LSI work?
In most cases, the most commonly used words in a given language do not carry any semantic value. That is why it is the first step that LSI performs – to remove these words in order to leave only the words of high importance for the content or defining the whole concept / meaning of the content. Although it sounds simple and easy, it is not and the way to define a word as a value for a given content are a lot, but the most common steps are:
- Remove alliances from the sentence
- Removal of prepositions
- Remove frequently used adjectives
- Remove commonly used adverbs
- Remove words that appear in any document in the index
- Remove words that appear in a single document
- Remove words like “however”, “because”, “though” and alike
- Removing pronouns
But this, as we mentioned in the previous sentence, is only part of the methods. The truth is that RankBrain’s LSI technology is “on the move” and analyzes each document individually and compares it to the other documents in the index while generating a general idea of which document should be rated relevant for each query that the user is looking for!
Why LSI?
Without latent semantic indexing SEO will face tremendous challenges and users will get search results that have nothing to do with their intention behind the query they have entered. These challenges stem from the Boolean search constraints, where there are only “real / false” values. This means that to retrieve information, you can refine your search with the AND, OR and NOT commands. This way you combine or exclude terms from your search.
As we all know, human language is not that simple. The two most common challenges when Boolean is used to search for text are synonyms (a few words that have similar meanings) and polysemy (words that have more than one meaning). We can imagine how using boolean search can return inappropriate results and / or skip the relevant information.
LSI searches for phrases related to the title of your page. Once a topic has been assigned to a specific page, it has the potential to rank the relevant search queries (or as SEO calls them, partial keyword matches) not only for the exact keyword matching queries but also for the related keyword queries words and phrases.
Serpact ™ tip: Create non-branded content ! This will ensure that search engines will see the link between your trademark and the services / products you offer (your non-branded keywords). Once you’ve completed your research to identify the topic and the group of keywords you want to target, always keep in mind the potential customers and visitors to your website: create insightful, engaging and unique blog posts.
In the end, you sell services and products to people rather than search engines!
A little more about LSI technology
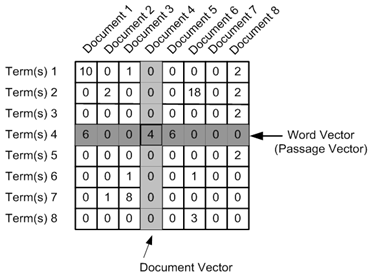
Once LSI filters words with important meaning for a given content as well as documents, the next step is to generate a term matrix. This is the concept of a very large network containing documents on the horizontal axis and containing words on the vertical axis. For each word in the list, we look at the line and set the number of times the word appears in the column for each document in which that word appears. If the word does not appear, we set zero.
Doing this for every word and document in our collection gives us mostly an empty network with a rare scattering on the horizontal axis. This network shows everything we know about our collection and document analysis. We can enumerate all content words in each document by looking at the horizontal axis in the appropriate column or finding all documents containing a certain content word by looking at the appropriate line.
Note that our ranking is binary – a square in our network contains either a digit or zero. This large network is the visual equivalent of generic keyword search that searches for exact match between documents and keywords.
The key step in LSI decomposes this matrix using a technique called single value degradation. The mathematics of this transformation is beyond the scope of this article, but we can get an intuitive understanding of what makes SVD (Singular Value Composition) by spatial thinking about the process.
Degradation to single value – Singular Value Composition
Imagine holding tropical fish and proud of your aquarium so much that you want to present a photo of a magazine. To get the best possible picture, you’ll want to choose a good angle from which to take the picture. You want to make sure that as much fish as possible is visible in your picture without being hidden from other fish in the foreground. You will also not want the fish to pull together, but rather to be shot from a corner that indicates they are well distributed in the water. Since your aquarium is transparent on all sides, you can take different images from above, below and from the entire aquarium and choose the best.
In a mathematical sense, you are looking for optimal mapping of points in a three-dimensional space (fish) in a plane (the film in your camera). “Optimal” can mean many things – in this case it means “aesthetically pleasing”. But imagine now that your goal is to keep the relative distance between the fish as much as possible so that the fish on opposite sides of the aquarium is not superimposed on the picture. Here you will do exactly what the SVD algorithm is trying to do with much more space.
Instead of mapping 3-dimensional space into 2-dimensional space, however, the SVD algorithm goes into much greater extremes. Typical space for terms can have tens of thousands of dimensions and be designed to be less than 150. However, the principle is the same. The SVD algorithm retains as much information as possible about the relative distances between document vectors, shrinking them down into a much smaller set of sizes. With this collapse, the information is lost and the content words superimpose each other.
Information loss sounds like a bad thing, but here it is positive. What we lose is the noise of our original matrix for a terminological document, revealing similarities that were hidden in the collection of documents. Similar things become more similar, while the inconsistent things remain different. This reductive mapping is what gives LSI its seemingly intelligent behavior that can connect semantically related terms. We really use ownership of the natural language, namely that words of similar significance tend to meet together.