How the neural networks change the search engines?

Neural networks are becoming an integral part of SEO optimization these days. As part of Machine Learning, they have established themselves as working models and a step forward to better understand user expectations and intentions behind search queries in search engines like Google.
Danny Sullivan announced about a month ago about launching these networks and searching for Google. The basic idea of the search engine is to create algorithms that are not so dependent on Information Retrieval algorithms. They identify themselves as independent, based on an entirely new technology, to judge the relevance of a document – to a phrase and vice versa.
Document Meaning Classification, also known as adhoc, is the task of classifying documents from a large collection using a query and just the text of each document. This contrasts with standard information retrieval (IR) systems that rely on text signals in connection with the network structure and / or user feedback.
Text-based ranking is particularly important when (i) user click information does not exist or is scarce, and (ii) the network structure of the document collection is non-existent or non-specific to focus on search queries.
What is neural matching?
Covering 30% of search queries, the nerve matching algorithm aims to match search queries and webpages. This method associates words with concepts. As voice search seems to be the next way to search in the coming years, the ability to better understand the concepts is important to the experience of Google users. There is something important here: this method does not rely on connection signals. However, it uses pages that are already ranked in certain positions.
How exactly does it work?
So, what can this neural matching algorithm perform? How can the results still be relevant? This method is based on ad hoc extraction. Document ranking (another name used for this field) uses the TF-IDF result and the cosine similarity to match the phrases in the documents and the needs expressed in the search queries.
Because the neuron matching algorithm uses only words in search queries to match concepts, the ad hoc extraction method is not sufficient. This is where artificial intelligence comes into play. Here, the technique of artificial intelligence, unattended, is used to advance the comprehension from words to concepts.
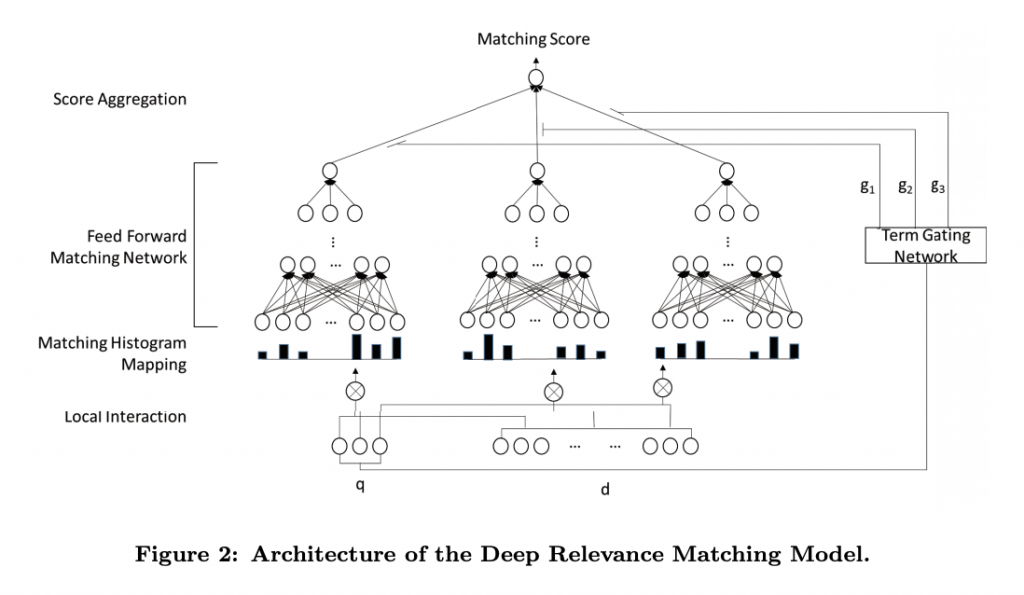
Backed by deep matching (DRMM) ad-hoc retrieval model, the neural matching algorithm is based on relevance. This method uses a collaborative deep architecture at the query term level, over and above the local query interactions and document compliance terms. To further address the issue of relevancy, engineers also create another model – AttentionBased ELement-wise DRMM, which draws attention to the weight of search query words in terms used in the document and prioritizing them in importance.
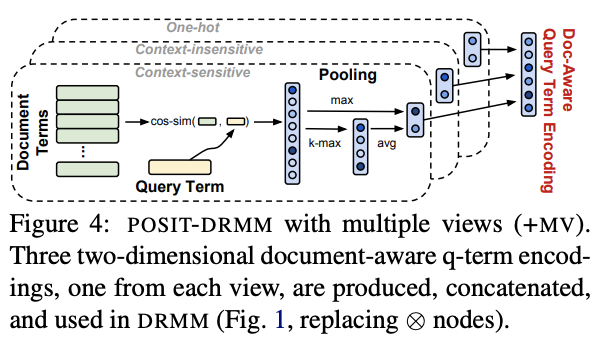
However, in order for the documents in search results to be sorted by relevance and quality, 2 more models have been created – POSIT-DRMM and Multiple Views of Terms (+ MV). The two models themselves can be the objects of 2 separate, detailed articles with complex and extremely technical and mathematical information, but we will nevertheless explain them in the next few lines.
The first model uses Max-Pooling and Average-Pooling calculations to calculate the relevance and correlation of words in a phrase and, respectively, the entire phrase, both maximally and averaged for greater precision. The first calculation derives the most strongly related concept from a phrase to the document, and the average similarity of all concepts with a link to the content of the document.
And a little deeper into relevance and ranking models
Context-sensitivity in understanding the terms
According to official information from Google, the search engine uses two rather important DRRM and PACRR models, over which Google software engineers have upgraded and created their own relevance and ranking models.
The first model – DRRM is based on the relationship between the query (or words from the query) to the words used in the document, but does not pay attention to the order in which the words in the query are arranged, as well as the semantic / semantic / semantic relation between them. the possible multiple connection between these words. The model has little sensitivity to the length of the phrase too.
The second model, PACRR, is based on the creation of a matrix that calculates the cosine proximity between the words in a query and the words used in the content of a document. The main advantage over the previous model is that it takes into account the order of words in a search query, calculates relevance based on n-gram convolutions, and draws attention to the connection with n-gram links at the density level.
How does Google solve the problem of the actual semantic / semantic / link between the words in the search queries and those in the content of the document?
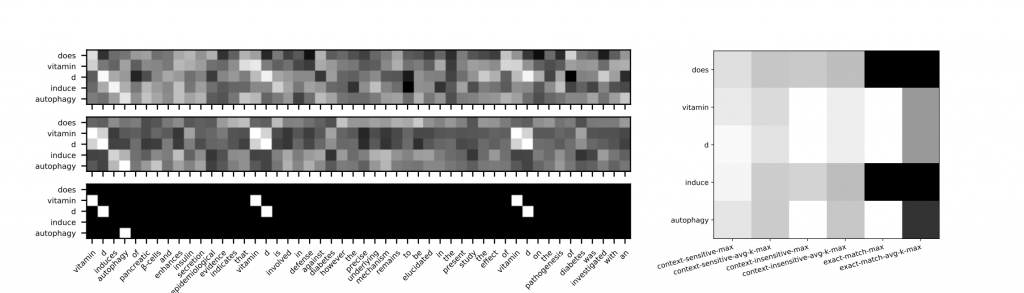
Google’s engineers combine the two models and refine them. The newly created model already addresses the words in a query individually as being important in determining the relevance to words in the content of a document. A model is also created to encode the context between the concepts in the query.
So while the first 2 models have no sensitivity to the context of the words in the documents and queries, this new model, called Context-sensitive Term Encodings, uses the basic practices of Information retrieval, namely the proximity of the phrases, the relationship between them, and the n- grams and their surrounding phrases, especially when evaluating the relationship of multiple search queries and used phrases in a document.
In the final, engineers decide to look at the concepts in phrases and documents from different angles. That’s why they call this model Multiple Views of Terms (+ MV). With it, POSIT-DRMM creates two-dimensional document-aware encoding for each term of a search phrase, examines the context of the semantic meaning between the words. The next two-dimensional view looks at the direct relationship between the words in the search phrase and the content of the document. There is also a third view, where words are arranged in vectors and viewed simultaneously as a direct link between words in a query and a document, relative to their semantic / semantic / semantic connection. Or, finally, we get a 6-look model that guarantees the maximum relevancy of ranked documents, styled into a model called: POSIT-DRMM + MV
What does this mean for SEO professionals?
Here, beyond all artificial intelligence issues, the question is, will this new algorithm affect those who create content on the web? What queries are included as part of the 30% that are covered by this new algorithm? We know that the RankBrain algorithm covers about 15% of search queries that have never been searched before.
One way or another, influence – not least, artificial intelligence, as well as machine learning in the study, classification and categorization of texts – is beginning to play an increasing role. At Serpact, we also notice daily improvements to Google, as well as some issues that we report to the search engine team on a regular basis.
How will we integrate this matching technique (in line with other rating signals at this time) into our daily workflow? From now on, SEOs who incorporate natural language processing techniques into their workflow should strive for semantic matching. However, relativity from the perspective of a super synonym (so-called Danny Sullivan) can still seem like a spam technique if it means including synonyms in the content.
We do not yet know enough about targeted inquiries or how content should be optimized. The current preservation of links – based on links between websites and sanctions for saturation with synonyms – can prevent uninformed attempts to optimize for neural matching. However, it is obvious that we will need to rethink how we create content in order to adapt.
However, some things are more than certain about what Google prefers as texts:
- Those that give an extremely good response to a query, regardless of its type
- Natural written content
- Content that contains phrases used in everyday online speech by potential users of a product, service, or information
- Content interactivity
- Multmedia content
- Content written by people, industry credentials
- Presence of entities
- Presence of topicality and sub-themes
- Presence of related phrases, etc.
For more information and to ensure that your content is semantically optimized at the moment, you can search the Serpaus Content Analysis service for a service that will explain in detail what is going on with your pages and why they are ranked or not ranked so well. You’ll also get recommendations on how to improve them.





