8 Приложения на Machine Learning при Търсещи Машини

Първите стъпки на machine learning, чисто информативно, датират още от 2009 – 2010 година , когато по световните технологични медии се заговори за интелигентни алгоритми, които се “учат” в движение , за да автоматизират и помагат за изпълнението на определени задачи , които ще спестят време и същевременно това изпълнение ще бъде по-качествено.
Постепенно започнаха да се предлагат open source библиотеки за machine learning, където всеки напреднал разработчик би могъл да създаде собствени алгоритми. Също така ще има възможност и да ги тренира на собствени бази от данни, за да започнат тези алгоритми да изпълняват тези задачи.
Как обаче machine learning влияе на оптимизацията за търсачки и можем ли наистина да направим нещо, за да оптимизираме сайтовете си? Да, можем, но частично и, разбира се, се изисква изключително високо ниво на познания и опит, за да успеем да оптимизираме за този вид съвкупност от алгоритми.
Ако трябва да се обобщят machine learning алгоритмите в няколко думитова са: алгоритми, създадени с цел да правят прогнози на база стойности, трендове, или други характеристики и променливи, въз основа на предишна информация или база от данни.
И докато machine learning алгоритмите намират приложение къде ли не, то търсещите машини са също едно от тези звена, където приложенията и тестовете им са непрестанни. В следващите редове ще открием 10 начина, при които търсачките като Гугъл използват т.нар machine learning, за да улесняват и забързват още повече работата си, като същевременно предоставят на потребителя още по-добри резултати и респективно по-добро преживяване.
Анализ на фрази на търсене и класификация
Едно от най-добрите приложения на machine learning алгоритмите е класифицирането на фрази на търсене и, съответно, документи от индекса на база на намерението на потребителя за търсене. Както знаем, фразите най-общо могат да бъдат – информационни, навигационни и транзакционни. Machine Learning алгоритмите отлично се справят с това да оценят фразата от страна на потребителя и да се обърнат към качеството на страниците, индексирани от търсачката, така че на база на тази информация + информацията по отношение на изследването на връзката между отделни фрази, тяхната взаимозаменяемост, оформянето на концепции и контект, както и събраната информация в исторически аспект /на база на потребителско поведение/ да се подаде най-добрият отговор към потребителя, под формата на резултати.
Потребителите може да търсят да купят (транзакционни), да научат нещо ново (информационно) или да намерят ресурси (навигация). Освен това една ключова дума може да бъде полезна за едно или всяко от тези намерения. Чрез анализиране на шаблоните за кликване и типа съдържание, с който потребителите се ангажират (напр. CTR по тип съдържание), търсачката може да използва machine learning, за да определи намерението на потребителя.
Един уникален пример за това е фразата “най-добрите ресторанти в софия”:

От скрийншота с органичните резултати става ясно, че алгоритмите са групирали и извели резултати, в които с приоритет е човешкото участие за оценка на ресторантите, форуми и ревюта, а на по-заден план остават обзорните статии по темата. Не на последно място, по фразата се появява и Local Pack, който класира ресторанти с голям брой ревюта. Всичко това дължим на machine learning алгоритмите, като допреди тях, Гугъл не се справяше толкова добре с групирането на резултатите и документи, на база намерение на потребителя спрямо заявката.
Откриване на шаблони при URL адресите и съдържанието на страниците
Търсачките използват machine learning algorithms за откриване на шаблони при URL адресите и body съдържанието на страницата, които помагат за идентифицирането на спам или дублиране на съдържание.
Те включиха общи атрибути на съдържание с ниско качество, като например:
- Наличие на няколко изходящи връзки към несвързани страници.
- Прекомерна употреба на едни и същи ключови думи
- Прекомерна употреба на синоними
- Преоптимизиране не анкор текстове
- Други подобни променливи.
Анализът на тези видове модели драстично намалява работната сила, която е нужна, за да се прегледа всичко от search quality raters.
Макар че все още има хора, които оценяват качеството, machine learning помогнa на Google автоматично да пресее страниците, за да премахне тези с ниско качество, без да е необходима човешка намеса. Machine learning е непрекъснато развиваща се технология, така че колкото повече страници се анализират, толкова по-точна е тя.
Идентификация на синоними
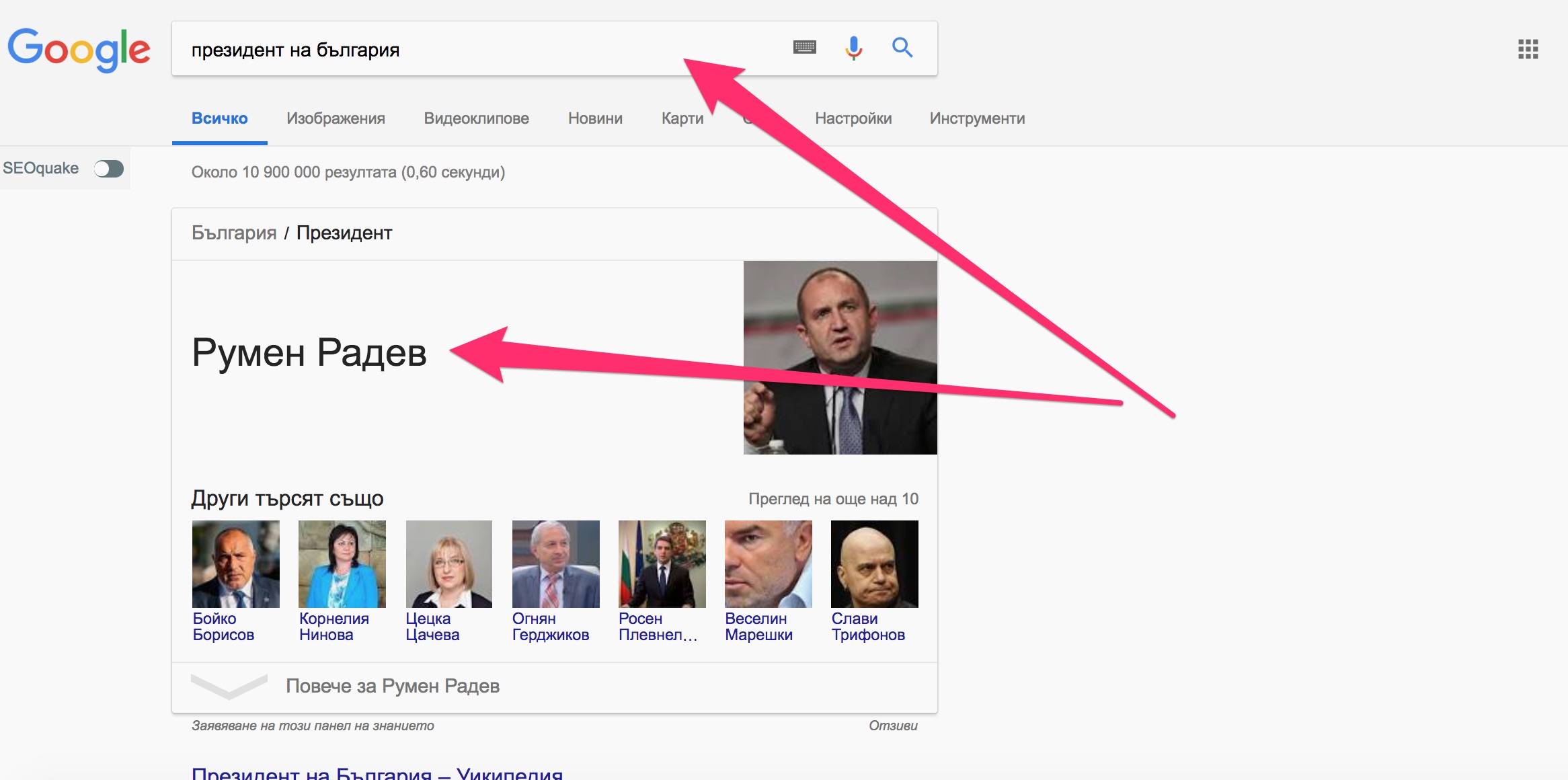
Когато видите резултати от търсенето, които не включват ключовата дума в даден фрагмент, това вероятно ще се дължи на това, че Google използва machine learning за идентифициране на синоними. Така ако въведем “президент на България” и “Румен Радев” резултатите ще са идентични.
По-добра идентификация на връзки между думите
Съвсем скоро Гугъл обявиха, че са създали нови алгоритми, основно касаещи класирането на документи – на база на оценка на заявка на търсене и оценка на релевантността на страницата директно. Това приложение на machine learning алгоритмите ще изиграе фундаментална роля за цялостната промяна на класиране на резултатите, тъй като по думи на Дани Съливан от Гугъл, новите алгоритми практически няма да използват линкове, за да класират резултати.
Съдържанието е по-важно. Това означава ли, че авторите на съдържание трябва да използват повече синоними? Всъщност не, защото претрупването със синоними е еквивалентно на насищането с една и съща ключова дума. Целта на Google да разбере чрез синонимите – контекста и значението на дадена страница. Да се създава съдържание с ясен и последователен смисъл, е много по-важно от спамването на страница с ключови думи и синоними.
Това, което Google официално заяви е, че е в състояние да разбере концепциите много по-добре, по начин, който надхвърля обикновените ключови думи и синоними. Това е по-естествено разбиране за начина, по който дадена уеб страница решава проблема, посочен от заявката за търсене.
Според официалното съобщение на Google:
“… сега стигнахме до момента, когато невронните мрежи могат да ни помогнат да направим значителен скок напред от разбирането на думите до разбирането на концепции. Невронните вграждания, подход, развит в областта на невронните мрежи, ни позволяват да преобразуваме думите в флъгерни представяния на основните понятия и след това да съгласуваме понятията в заявката с концепциите в документа. Ние наричаме тази техника невронно съвпадение. “
Идентифициране на приликите между думите в заявка за търсене
Не само данните от заявките се използват от машинното обучение, за да идентифицират и персонализират по-късните заявки на потребителя, но също така помага да се създадат модели в данните, които оформят резултатите от търсенето, които получават другите потребители.
Google Trends е страхотен пример за това. Фраза или дума, която не означава нещо първоначално, може да има безсмислени резултати от търсенето. Въпреки това, тъй като фразата (и следователно потребителските търсения) се използва повече с течение на времето, машинното обучение може да показва по-точна информация за тези заявки. Тъй като езикът се развива и трансформира, машините са способни да прогнозират нашите значения зад думите, които казват, и да ни предоставят по-добра информация.
Търсене на изображения за разбиране на снимки
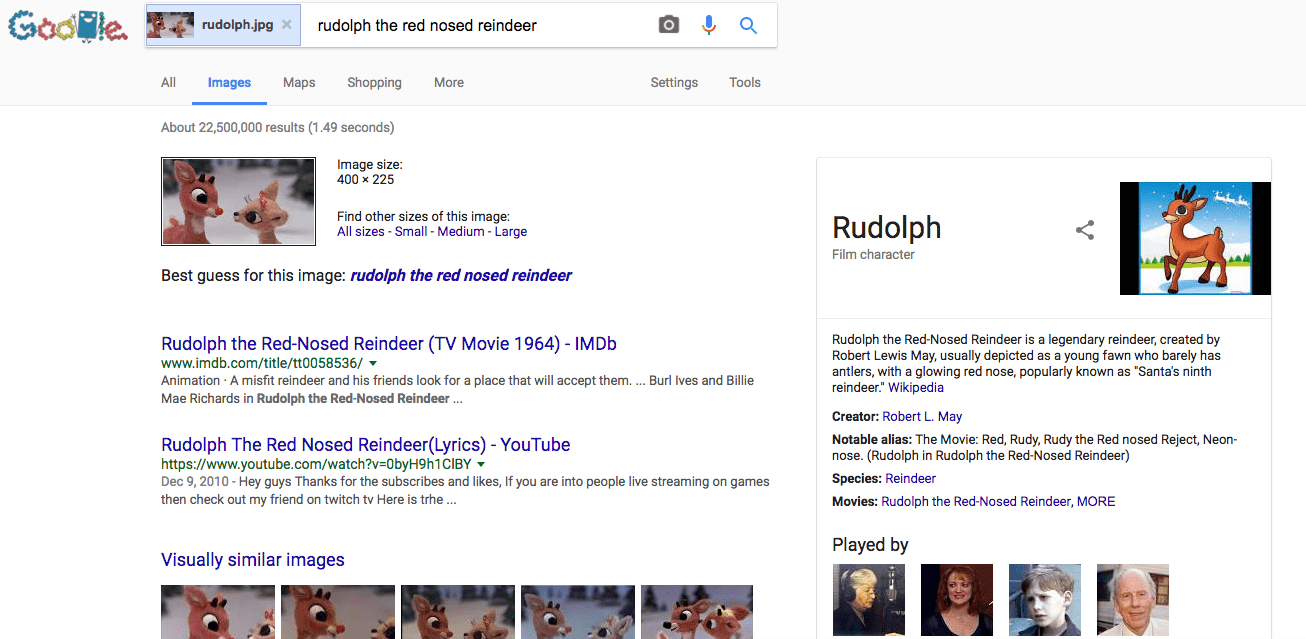
Тази задача е идеална за машинно обучение, защото може да анализира цветове и форми и да се обърне към всички съществуващи структурни данни за снимката, за да помогне на търсачката да разбере какво представлява изображението. По този начин Google може не само да каталогизира изображения за резултатите от търсенето с изображения на Google, но и да задейства функцията, която позволява на потребителите да търсят по файл с снимки (вместо текстова заявка).
След това потребителите могат да намерят други копия на снимката онлайн, както и подобни фотографии, които имат същите теми или цветова палитра, както и информация за предметите в снимката.
Персонализирани сигнали въз основа на конкретни заявки
Machine learning алгоритмите може да поставят повече тежест върху променливи при някои заявки пред други. Търсещата машина “се учи” за предпочитанията на конкретен потребител и може да базира информацията си върху минали заявки, за да представи възможно най-интересната информация. Като цяло по данни на потребителски изследвания, персонализираните фрази чрез machine learning, са увеличават процентът на кликване (CTR) на резултатите с около 10%.
Например, ако потърси “футболен стадион в Ню Йорк” в браузър “инкогнито”, получавам отговора на “Стадион MetLife”.
След това, ако търся в един и същ браузър само за “джетове”, Google приема, че тъй като последната ми заявка беше за футболен стадион, тогава тази заявка е също така за футбола.
Идентифициране на нови сигнали
Според подкаст от 2016 г., извършен с Гари Илийс от Google, RankBrain не само помага да се идентифицират patterns в заявките, но и помага на търсещата машина да идентифицира възможните нови сигнали за класиране. Тези сигнали се търсят, за да може Google да продължи да подобрява качеството на резултатите от заявките за търсене.
Илийс също така спомена в епизода на подкасти, че повече от сигналите на Google могат да се основават на машинно обучение.
Тъй като търсачките могат да “обучават” технологии как да правят прогнози и данни сами, може да има по-малък човешки труд и служителите да могат да се движат към други неща, които машините не могат да направят, като иновации или проекти, насочени към хора.
Въвеждането и разработването на machine learning тепърва ще ни учудва и замайва, тъй като тези алгоритми активно участват дори в т.нар. гласово търсене, което Гугъл разработват усърдно. Machine learning обаче с времето ще промени доста подходите за SEO оптимизация на сайтове, както и начините за изготвяне на съдържание. С времето то ще стане много по-важно, но не само като част от общата стратегия, а като водеща такава и то с изискване за високо ниво на качество, освен за подаване на най-правилния отговор към потребителя.





