Алгоритмични модели за класиране на резултати при търсачките
През последните години, с бързия растеж на световната мрежа и трудностите в намирането на желана информация, ефикасни и ефективни системи за извличане на информация са станали по-важни от всякога, а търсачката се е превърнала в основен инструмент за много хора. Системата за класиране, централен компонент във всяка търсачка, отговаря за съвпадението между обработени заявки и индексирани документи.
Поради централната си роля, голямо внимание бе отделено и продължава да се отделя на изследванията и развитието на технологиите за класиране. Освен това класирането е от основно значение и за много други приложения за извличане на информация, като филтриране, отговор на въпроси, извличане на мултимедия, обобщаване на текст и онлайн реклама. Използването на технологиите за машинно обучение в процеса на класиране доведе до иновативни и други ефективни модели за класиране и доведе до появата на нова изследователска област на име – обучение за класиране или Learn-to-Rank.
Преди да пристъпим към разглеждането на моделите е важно да се подчертае, че няма единни модели за класиране и, че всеки модел или група от модели се използват, според съответният проблем, който трябва да бъде разрешен. Има много различни сценарии и модели за класиране, които представляват интерес за извличане на документи. Например, понякога трябва да класираме документи чисто според тяхната релевантност по отношение на заявката. В някои други случаи трябва да разгледаме връзките на сходство, структура на уебсайтове и разнообразие между документите в процеса на класиране. Това също се нарича релационно класиране.
Конвенционални модели за класиране
В литературата за извличане на информация са предложени много модели за класиране. Те могат да бъдат грубо категоризирани като модели за класиране по релевантност и такива по важност.
Модели за класиране по релевантност
Целта на модела за класиране на релевантността е да се изготви списък с класирани документи според релевантността между тези документи и заявката на търсене. Въпреки че не е необходимо, за по-лесно изпълнение, моделът за класиране на релевантността обикновено взема всеки индивидуален документ като входни данни и изчислява резултат, измерващ съответствието между документа и заявката. След това всички документи са сортирани по низходящ ред съгласно техните резултати.
Ранните моделите за класиране по релевантност извличат документи въз основа на появата на понятия / думи от заявката на търсене. Примерите включват булевия модел. По принцип тези модели могат да предвидят дали един документ е от значение за заявката или не, но не могат да предвидят степента на релевантност.
За допълнително моделиране на степента на релевантност е предложен моделът Vector Space (VSM). И документите, и запитванията са представени като вектори в Евклид пространство, в което вътрешното калкулиране на два вектора може да се използва за измерване на приликите им. За да получите ефективно векторно представяне на заявката и документите, изчисляването на TF-IDF се използва широко.
Популярни модели:
- BM25
- VSM
- LSI- Latent Semantic Indexing
- Language Model For Information Retrieval – LMIR
Модели за класиране по важност
 Един от най-популярните модели тук е така нареченият PageRank модел. PageRank използва като основен критерии вероятността потребител, който произволно да кликне върху връзки да бъде отведен на конкретна уеб страница, за да отчете вероятността за тежест на даден линк. Много алгоритми са разработени с цел допълнително подобряване на точността и ефективността на PageRank. Някои се фокусират върху ускоряването на изчисленията, докато други се фокусират върху усъвършенстването и обогатяването на модела. Примери за това са topical-sensitive PageRank и зависимият от заявки PageRank. Приема се, че връзки от страници с еднаква тематика ще тежат повече от връзки с друга тематика.
Един от най-популярните модели тук е така нареченият PageRank модел. PageRank използва като основен критерии вероятността потребител, който произволно да кликне върху връзки да бъде отведен на конкретна уеб страница, за да отчете вероятността за тежест на даден линк. Много алгоритми са разработени с цел допълнително подобряване на точността и ефективността на PageRank. Някои се фокусират върху ускоряването на изчисленията, докато други се фокусират върху усъвършенстването и обогатяването на модела. Примери за това са topical-sensitive PageRank и зависимият от заявки PageRank. Приема се, че връзки от страници с еднаква тематика ще тежат повече от връзки с друга тематика.
Предложени са също алгоритми, които могат да генерират стабилно класиране по важност спрямо спам за връзки. Например TrustRank е алгоритъм за класиране на важността, който взема предвид надеждността на уеб страниците при изчисляване на важността на страниците. В TrustRank набор от надеждни страници първо се идентифицират като начални страници. Тогава доверието на началната страница се разпространява към други страници в графиката на уеб линковете. Тъй като разпространението в TrustRank започва от надеждни страници, TrustRank може да бъде по-устойчив на спам от PageRank.
Оценки, базирани на позиции на ниво заявка
Предвид големият брой модели за класиране, е необходим стандартен механизъм за оценка, за да се избере най-ефективният модел. Всъщност оценката изигра много важна роля в историята на извличане на информация. Извличането на информация е емпирична наука и тя е лидер в компютърните науки за разбиране значението на релевантността и сравнителния анализ. Извличането на информация е добре обслужено от експеримента на Cranfield методологията, която се основава на съвместни сборници от документи, информационни нужди (запитвания) и оценки на релевантността.
Чрез прилагане на парадигмата Cranfield към извличане на документи, съответният процес на оценка може да бъде описан по следния начин:
- Събиране на голям брой (случайно извадени) заявки за формиране на тестов набор.
- За всяка заявка q- Събирайте документи {dj} m j = 1, свързано със заявката.
- Вземете преценката за уместността на всеки документ чрез човешка оценка.
- Използвайте даден модел за класиране, за да класирате документите.
- Измерете разликата между резултатите от класирането и преценката за уместността като се използва мярка за оценка.
- Използвайте средната мярка за всички заявки в тестовия набор, за да оцените ефективността на модела за класиране.
Що се отнася до събирането на документите, свързани с заявка, могат да се използват редица стратегии. Например, човек може просто да събере всички документи, съдържащи заявената дума. Човек също може да избере да използва някои предварително определени класиращи системи, за да получи документи, които е по-вероятно да бъдат уместни.
Популярна стратегия е методът на обединяване, използван в TREC. При този метод се създава пул от евентуално релевантни документи чрез вземане на извадка от документи, избрани от различните участващи системи. По-специално, най-добрите 100 документи, получени във всеки подаден цикъл за дадена заявка, са избрани и обединени в пространството за човешка оценка.
Learn-to-Rank & Machine Learning
В предишния раздел бяха представени много модели за класиране, повечето от които съдържат параметри. Например в BM25 има параметри k1 и b, параметър λ в LMIR и параметър α в PageRank. За постигане на сравнително добро класиране (по отношение на мерките за оценка), тези параметри трябва да бъдат настроени с помощта на валидиращ набор. Независимо от това, настройка на параметри далеч не е тривиално, особено като се има предвид, че мерките за оценка са прекъснати и недиференцируем по отношение на параметрите.
В допълнение, модел перфектно настроен на набора за валидиране (training set) понякога се представя лошо при невиждани тестови заявки. Това обикновено се нарича over-fitting. Друг е въпросът относно комбинацията от модели за класиране. Като се има предвид, че в литературата са предложени много модели, така е естествено е да проучите как да комбинирате тези модели и да създадете още по-ефективен нов модел. Това съчетаване и ефективността му, обаче, все още са под въпрос.

Докато изследователите по извличане на информация описваха и търсеха решение на тези проблеми, машинното обучение демонстрира своята ефективност в автоматичната настройка на параметрите, в комбинирането на множество характеристики и в избягването на прекомерното приспособяване. Следователно това изглежда доста обещаващо да се възприемат технологиите за машинно обучение за решаване гореспоменатите проблеми при класирането.
Въпреки това, повечето от най-съвременните алгоритмите за обучение за класиране научават оптималния начин за комбиниране на необходимите функции от двойки запитвания и документи чрез дискриминативно обучение. Методи за класиране имат следните две свойства, по които можем да ги разделим и на 2 вида:
Featured based
Функция, базирана на „Въз основа на характеристиките“ означава, че всички документи, които се изследват са представени от вектори на характеристики, отразяващи съответствието на документите спрямо заявката за търсене. Тоест, за дадена заявка q, свързаният с нея документ d може да бъде представен с вектор x = Φ (d, q), където Φ е екстрактор на функции. Типични характеристики, използвани при обучението за класиране включват честотите на заявените термини в документа, изходните данни на модела BM25 и модела PageRank и дори връзката между даден документ и други документи. Тези характеристики могат да бъдат извлечени от индекса на търсещата машина.
Дори ако функция е изходът на съществуващ модел за извличане, в контекста на обучаването на класиране се приема, че параметърът в модела е фиксиран и обучението се осъществява по оптималният начин за комбиниране на тези характеристики. В този смисъл автоматично настройване на параметрите на съществуващите модели преди, не е категоризирано като методи за „обучение за класиране“.
Възможността за комбиниране на голям брой функции е предимство на методи за обучение за класиране. Лесно е да включите всеки нов напредък при извличането модел, като включва изхода на модела като едно измерение на характеристиките. Това важи за популярните търсачки, тъй като е почти невъзможно да се използват само няколко фактора за задоволяване на сложните информационни нужди на потребителите в мрежата.
Discriminative Training
Дискриминативно обучение „Дискриминативно обучение“ означава, че учебният процес може да бъде добре описан от четирите компонента на дискриминативното обучение – input, output, hypothesis, training set with loss function. Тоест, методът на обучение за класиране има своите собствено входно пространство, изходно пространство, пространство на хипотези и функция на загуба.
В литературата за машинно обучение дискриминационните методи са широко разпространени използва се за комбиниране на различни видове характеристики, без необходимостта от определяне на вероятностна рамка, която да представя генерирането на обекти и правилността на прогнозирането.
Дискриминативното обучение е автоматичен процес на обучение, основан на обучението данни. Това също е едно от изискванията към популярните търсачки за имплементация, защото всеки ден това търсачките ще получават много потребителски отзиви и данни.
Learn-to-Rank Framework
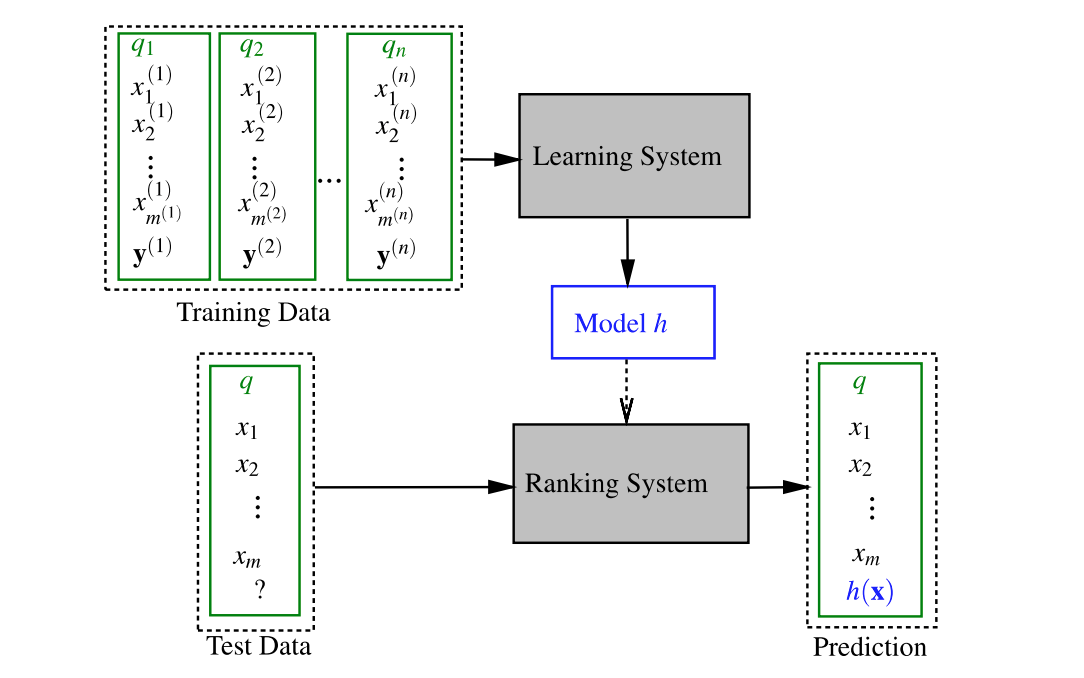
От фигурата виждаме, че при обучението за класиране кат вид контролирано обучение, е необходим набор от обучения. Типичният набор за обучение се състои от n тренировъчни заявки qi (i = 1, …, n), техните свързани документи, представени от вектори на функции x (i) = {x (i) j} m (i) j = 1 (където m (i) е броят на документите, свързани с заявка qi), и съответните преценки за уместност. Тогава се използва специфичен алгоритъм за учене, за да научи модела за класиране (т.е. начинът на комбиниране на характеристиките), така че изходът от модела за класиране може да предвиди етикета на основната истина в тренировъчния набор възможно най-точно по отношение на функция на загуба. Във фазата на тест, когато се появи нова заявка, моделът, научен във фазата на обучение, се прилага за сортиране на документите и връщане на съответния класиран списък на потребителя като отговор на неговото запитване.
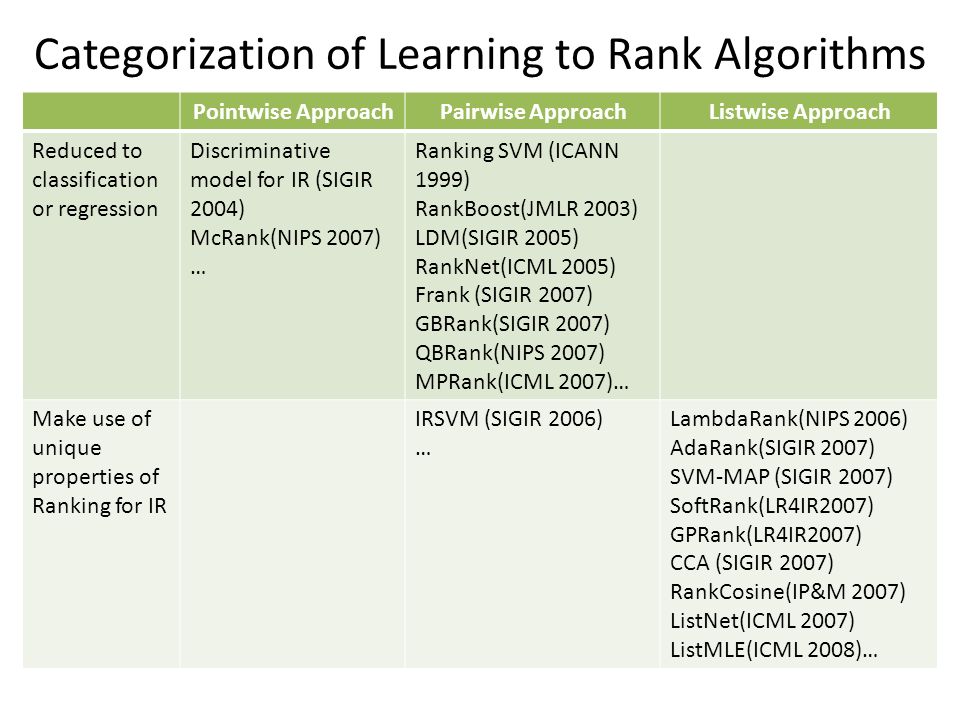
Основни подходи към обучението за класиране
Pointwise ранкинг

Когато използваме технологиите за машинно обучение за решаване на проблема с класирането, вероятно най-простият начин е да се провери дали съществуващите методи на обучение могат да се прилагат директно. Правейки това, човек приема, че точната степен на релевантност на всеки документ е това, което моделите ще прогнозират, въпреки че това може да не е необходимо, тъй като целта е да се постигне класиран списък на документите. Според различните използвани технологии за машинно обучение, pointwise подходът може да бъде разделен допълнително на три подкатегории: алгоритми, базирани на регресия, алгоритми, базирани на класификация, и алгоритми, базирани на ординална регресия.
За алгоритмите, базирани на регресия, изходното пространство съдържа реално оценени по значение резултати; за алгоритмите, базирани на класификация, изходното пространство съдържа неподредени категории; и за алгоритмите, базирани на ординалнаа регресия, изходното пространство съдържа подредени категории.
Точковите подходи разглеждат един документ в даден момент във функцията за загуба. Те по същество вземат един документ и обучават класификатор / регресор върху него, за да предскажат колко е подходящ за текущата заявка. Окончателното класиране се постига чрез просто сортиране на списъка с резултати по тези документи. При точковите подходи оценката за всеки документ е независима от другите документи, които са в списъка с резултати за заявката. Всички стандартни алгоритми за регресия и класификация могат да бъдат директно използвани за pointwise oбучение за класиране.
Входното пространство на точковия подход съдържа вектор на всеки елемент – документ. Изходното пространство съдържа степента на съответствие – релевантност на всеки един документ. Различните видове преценки могат да бъдат превърнати в основни етикети на истината по отношение на релевантността като степен:
- Ако решението е дадено директно като степен на уместност lj, етикетът за основна истина за документ xj се определя като yj = lj.
- Ако преценката е дадена като двойно предпочитание – pairwise lu, v, човек може да получи етикат като основна истина, като се брои честотата на документ спрямо други документи.
- Ако преценката е дадена като общия ред πl, може да се получи етикета на основната истина чрез използване на функция за мапинг. Например позицията на документа в πl може да се използва като основна истина.
Видове:
- Модели базирани на регресия
- Модели базирани на класификация
- Модели базирани на ординална регресия
Pairwise класиране
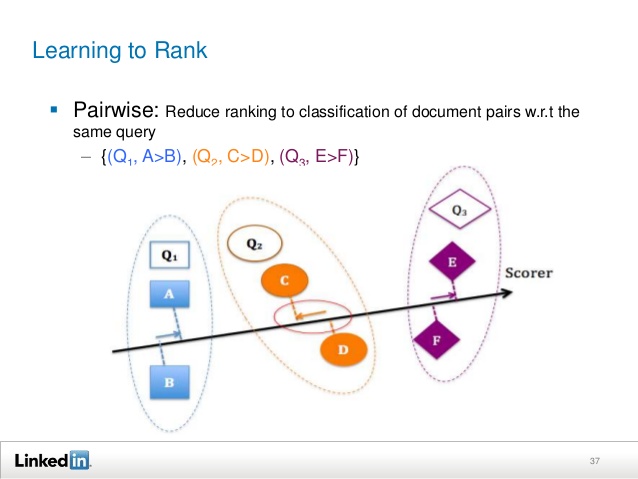 Подходът по двойки не се фокусира върху точното прогнозиране на степента на уместност на всеки документ, а вместо това се грижи за относителния ред между два документа. В този смисъл той е е по-близък до концепцията за „класиране“, отколкото pointwise подходът.
Подходът по двойки не се фокусира върху точното прогнозиране на степента на уместност на всеки документ, а вместо това се грижи за относителния ред между два документа. В този смисъл той е е по-близък до концепцията за „класиране“, отколкото pointwise подходът.
При двойния подход класирането обикновено се свежда до класификация на двойки документи, т.е. за да се определи кой документ в двойка е предпочитан. Тоест целта на обучението е да се сведе до минимум броят на пропуснатите класифицирани двойки документи. В краен случай, ако всички двойки документи са правилно класифицирани, всички документи ще бъдат правилно класирани. Обърнете внимание, че тази класификация се различава от класификацията в pointwise подходеът, тъй като той действа на всеки два документа, които се изследват.
Естествено притеснение е, че двойките документи не са независими, което нарушава основно предположение за класификация. Факт е, че въпреки че в някои случаи това предположение наистина не е вярно, все пак може да се използва класификационна технология, за да се научи на класиране модел. Необходима е обаче друга теоретична рамка, за да се анализират обобщените данни на учебния процес на модела.
Модели:
- SortNet
- RankNet
- FRank
- Rank Boost
- Модели базирани на преференция
- Ranking SVM
- GBRank
- Multiple Hyperplane Ranker
- Magnitude-Preserving Ranking
- IR-SVM
- Robust Pairwise Ranking with Sigmoid Functions
- P-norm Push
- Ordered Weighted Average for Ranking
- LambdaRank
- Robust Sparse Ranker
- LambdaMart
Listwise Класиране
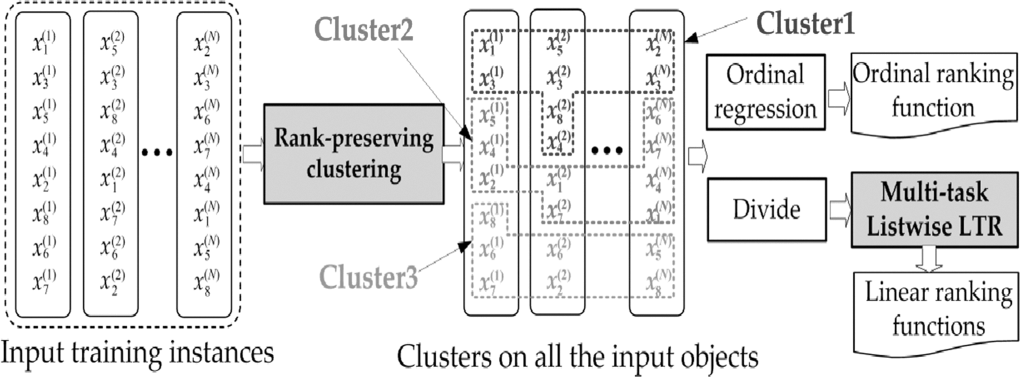
Подходите на Listwise директно разглеждат целия списък с документи и се опитват да изградят оптималното им подреждане. Съществуват 2 основни под-техники за правене на списъци:
- Поучаване за класиране: Пряка оптимизация на IR метрики като NDCG. Например SoftRank, AdaRank.
- Минимизирайте функция за загуба, която се определя въз основа на разбирането на уникалните свойства на вида класиране, който сe опитвате да постигнете. Например ListNet, ListMLE. Подходите от списъка могат да бъдат доста сложни в сравнение с pairwise или pointwise подходите.
Входното пространство на списъчния подход съдържа набор от документи, свързани с заявка q, например, x = {xj} m j = 1. Изходното пространство на списъчния подход съдържа списъка с класиране (или пермутация) на документите. Различните видове преценки могат да бъдат превърнати в основи етикети за истинност по отношение на класиран списък:
- Ако преценката е дадена като степен на релевантност lj, тогава всички пермутации, които са в съответствие с преценката, са основни истински пермутации. Тук определяме пермутация πy като съответстваща на степента на уместност lj, ако ∀u, v удовлетворяваща lu> lv, винаги имаме πy (u) <πy (v). В този случай може да има множество основни истини. Използваме Ωy, за да представим множеството от всички такива пермутации.
- Ако преценката е дадена като двойни предпочитания, тогава отново всички пермутации, които са в съответствие с двойните предпочитания, са пермутации на основна истина. Тук дефинираме пермутация πy като последователна с предпочитанията lu, v, ако ∀u, v удовлетворяващи lu, v = +1, винаги имаме πy (u) <πy (v).
- Отново може да има и множество основни истинни пермутации в този случай и ние използваме Ωy, за да представим множеството от всички такива пермутации.
Подобно лечение може да се намери в определението за ранк корелация:
- Ако преценката е дадена като общия ред πl, може да се определи пряко πy = πl. Обърнете внимание, че при списъчния подход изходното пространство, което улеснява процеса на обучение, е точно същото като изходното пространство на задачата. В тази връзка теоретичният анализ на списъчния подход може да има по-пряка стойност за разбирането на реалния проблем с класирането, отколкото другите подходи, когато има несъответствия между изходното пространство, което улеснява обучението, и реалното изходно пространство на задачата. Пространството на хипотезата съдържа многопроменливи функции h, които работят на набор от
документи и прогнозират тяхната пермутация.
По практически причини хипотезата h обикновено се реализира с функция за оценка f, например h (x) = сортиране ◦ f (x). Тоест, първо се използва функция за оценяване f, за да се даде оценка на всеки документ, след което тези документи се сортират в низходящ ред на резултатите, за да се получи желаната пермутация.
Има два вида функции на загуба, широко използвани в listwise подхода. За първия тип функцията на загуба е изрично свързана с мерките за оценка (които наричаме функция за загуба, специфична за измерването), докато за втория тип функцията на загуба не е свързана. Обърнете внимание, че понякога не е много лесно да се определи дали функцията на загуба е пореднa, тъй като някои градивни елементи на загуба от списъчен ред също могат да се разглеждат pointwise или pairwise.
В тази статия ние разграничаваме главно загубата по ред от точкова или двойно загуба според следните критерии:
- Функцията за загуба на списък се дефинира по отношение на всички документи, свързани с заявка
- Функцията за загуба на списък не може да бъде напълно разградена до просто сумиране върху отделни документи или двойки документи
- Функцията за загуба на списъка подчертава концепцията за класиран списък и позициите на документите в крайния резултат са видими.
Видове и модели:
Minimization of Measure-Specific Loss
- Measure Approximation
- Bound Optimization
- Non-smooth Optimization
Minimization of Non-measure-Specific Loss
- ListNet
- ListMLE
- Ranking Using Cumulative Distribution Networks
- BoltzRank