Google Patent Analysis: Related entities when searching for phrases that require knowledge

Google patents are one of the key documents through which a search engine legally presents and protects the technologies it integrates into its services. One of the most interesting, informative, and worthwhile reading times is patents dedicated to Google Search, or put another way – what algorithms Google has in place to rank the results of a given search query. Despite the 200 factors behind Google’s ranking, the truth is that they are actually over 3000.
Although very popular in digital marketing professionals write that ranking factors are common, there are actually none, because each phrase and each semantic core could have its own factors after RankBrain was introduced.
What exactly does the Knowledge Graph do?
At the heart and heart of Google is the so-called Knowledge Graph, which can generally be explained as a storehouse of knowledge, but not just related to certain phrases, but interfering with the interpretation of the phrases that users enter when searching. This happens as the graph examines in real time the entities we introduce as part of the queries. In addition, its primary purpose is to answer a search engine question, just as a person would do in a conversation with you.
In January 2018, a Google patent was guaranteed that the search engine evaluates related entities when analyzing phrases that include such entities and that require some knowledge that is derived from Google Knowledge Graph and presented in the form of Google results.
If we have to think in a little more depth, this means that SEO optimization and word processing is even more complicated, because the real point of view here is not about enriching the text with just related words, synonyms and all variations of words, but much more!
Proof of this is the following from the patent:
In some implementations, a computer-implemented method comprises identifying in a knowledge graph, using at least one processor, at least one entity and related entities related to the at least one entity by respective properties. The computer-implemented method comprises, for each respective one of the related entities, determining, using at least one processor, a related entity score associated with a respective property that relates the at least one entity and the respective one of the related entities. The computer-implemented method comprises, for each respective property, generating a property score, using at least one processor, based on related entity scores associated with that respective property. The computer-implemented method comprises generating, using at least one processor, and causing to be stored a data structure of sortable properties based on the generated property scores, wherein the data structure is usable to provide sorted search results in response to a query.
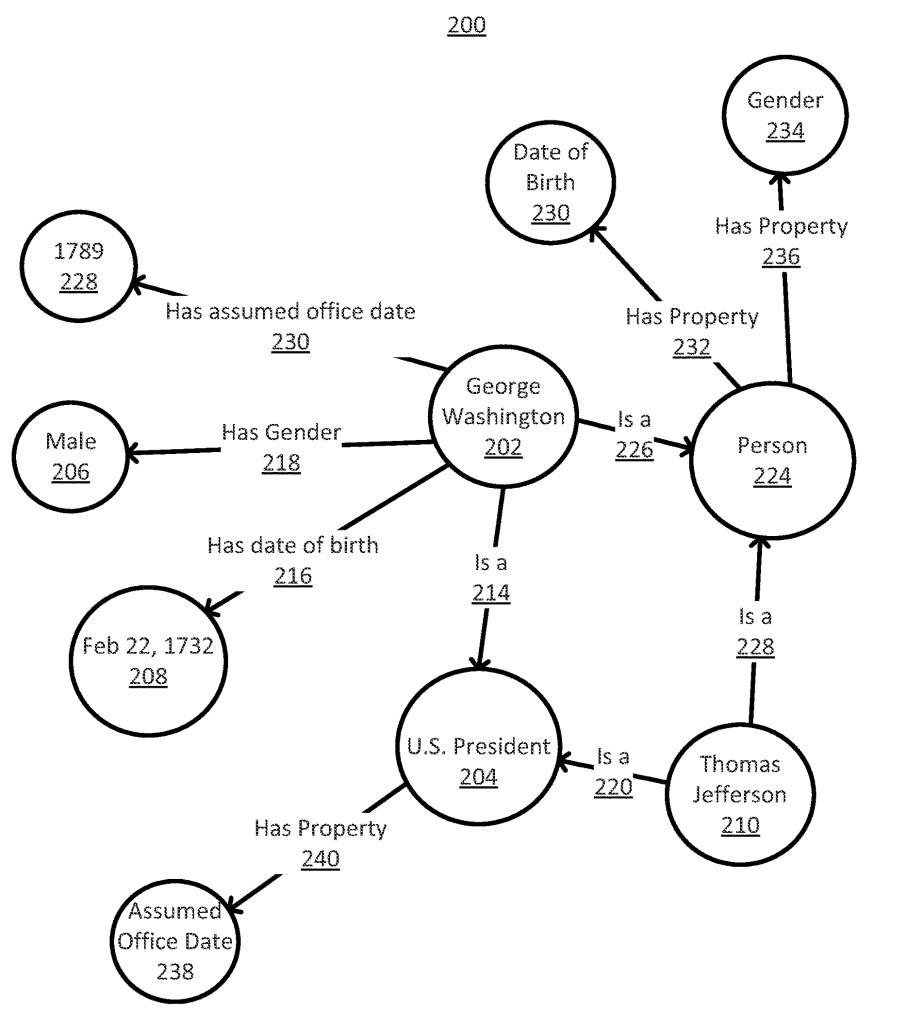
What are related entities?
According to the patent summary:
An entity may be related to multiple related entities by one or more properties, and the entity may also be associated with one or more entity types. A system for providing sorted results may include identifying the entity, related entities, and types. The system may also determine related entity scores for each respective related entity, relative to the entity.
For each property, the related entity scores of the related entities related to the entity by that property are combined to generate a property score. The properties are then sorted based on their property scores. The sorting may occur for properties associated with an entity type, and sorted search results may be provided as output for one or more entity types of interest.
Thus, in its essence, the patent aims to inform us and to suggest that the Knowledge Graph is already part of the analysis of search queries in a very serious way, especially when we ask Google a question. An entity / object, person, location, landmark, or simply something that exists or has already been defined / can and is related to many other entities. The relationship between an entity and a plurality of entities is based on one or more properties. These entities can also be classified into types and a specific entity associated with certain types of merged entities.
In Google’s case, this is the way it works to first identify an entity, and then search for related entities as well as types of entities. They are also given a certain value, which the higher the more semantically related an entity is to another. For each property, the values of the related entities to a particular entity by a particular property are combined to form an inherent value of the relatedness.
The properties, of course, are then pooled on the basis of the intrinsic value. Sorting can also be by properties related to a particular type of entity and based on that sorted results in the search engine appear, based on the entity of interest.
Related entities can also be ranked in Google’s algorithm – How exactly does this work?
Based on information from another patent (Related Entities), Google ranks internal entities based on:
- How often does one search for a related entity after applying for the first entity.
- How popular is the connected entity globally
- How often a recognized reference with related entity information related to an entity also appears in the search query entered, such as a recognized reference to the original entity.
- Is there information that 2 or more related entities, part of the second entity type, are part of a collection of entities in a specific order? – for example, if it is a person who has children and they are arranged according to their date of birth in the information.
- If there is information that indicates that 2 or more related entities are part of a larger entity that is more recognizable, then the two entities will be replaced by the larger entity.
What exactly are values of connected entities?
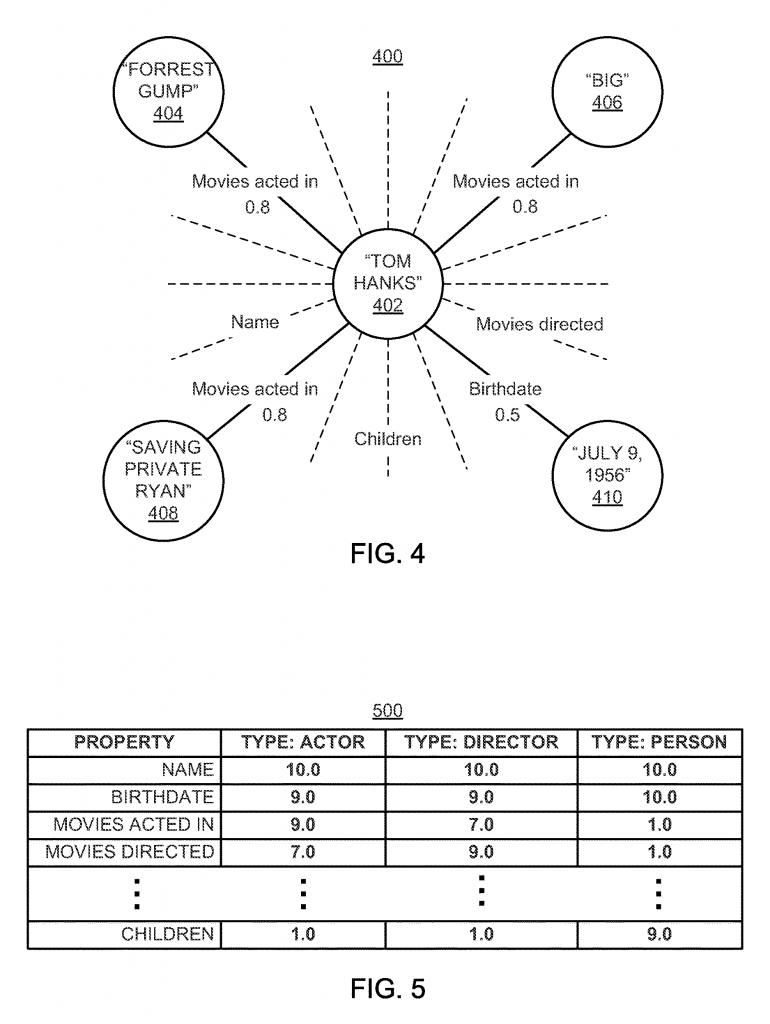
According to Google’s patent:
In some implementations, a system comprises a data structure comprising a knowledge graph, and one or more processors. The one or more processors are configured to perform operations comprising identifying in the knowledge graph at least one entity and related entities related to the at least one entity by respective properties. The one or more processors are configured to perform operations comprising, for each respective one of the related entities, determining a related entity score associated with a respective property that relates the at least one entity and the respective one of the related entities. The one or more processors are configured to perform operations comprising, for each respective property, generating a property score based on related entity scores associated with that respective property. The one or more processors are configured to perform operations comprising generating and causing to be stored a data structure of sortable properties based on the generated property scores, wherein the data structure is usable to provide sorted search results in response to a query.
Related entity scores associated with each particular property may be combined for that property. For example, referencing FIG. 4, the related entity scores for related entities “Forrest Gump,” “Big,” and “Saving Private Ryan” may be summed to give a sum for the property “Movies acted in,” e.g., 0.8+0.8+0.8=2.4. In a further example, the related entity scores may be combined as a weighted sum. Any suitable combination of related entity scores may be used to generate the property score. In some implementations, one or more types may be a subtype of another entity type. For example, referencing data structure 550 of FIG. 5, the type “Actor” may be a subtype of the entity type “Person,” which may be referred to as a parent type relative to the subtype. In some such implementations, for the parent type, the property score for each property of each subtype may be summed with the same property of the parent type. For example, referencing data structure 550 of FIG. 5, property “Movies acted in” is included in type “Actor” and “Person,” and accordingly, the property score of 9.0 for the entity type “Actor” may be aggregated to the property score 1.0 for the entity type “Person.” The one or more processors may renormalize, scale, weight, or otherwise alter the scores within the parent type after incorporating the subtype.
In other words, if we are to summarize the concept, then we will come to the following conclusions about exactly how technology works:
- 1 or 2 processors that perform operations designed to recognize at least one entity of a Knowledge Graph and an associated entity based on certain properties.
- 1 or 2 processors perform operations designed to determine for each of the associated entities the value of its relatedness associated with a particular property that refers to the original entity that we referred to as its related entities.
- 1-2 processors are also used in a system that perform functions intended to give a connection value of each property based on the value of the connection between the associated entities associated with that property.
- 1-2 processors are also used that perform functions designed to collect all information in a data structure that can be sorted and sorted based on the generated connectivity values, where these data structures are used to give ordered results when searching for a phrase on Google.
- Related entities and their values associated with certain properties can be grouped around these properties. An example of this is Figure 4.
- In another example, the value of connectedness between related entities can be calculated as a sum of weights. Any additional information can also be used to generate the value of connectivity and properties.
- In some cases, certain types of related entities may be classified into a particular type and be a subtype of other types of entities. Proof of this is Figure 5, where “Actor” is a subtype of “Person,” which can be referred to as the parent type associated with the subtype or subtype. In this case, the value of the connectivity between the properties of each subtype can be summed with the same property of the parent parent type.Example: If we look at the table in figure 5, we will see that the property “Movies acted in” is included in the type “Actor” and “Person,” and accordingly the value of connectivity of the property – 9.0 for the nature of type “Actor” can be aggregated with a connectivity value of 1.0 for a Person type entity.
Or (if we have to shorten the concept even further), it extracts information from the Graph for a particular entity, examines related entities on the basis of a specific property, and adds value to the connection between the entities as well as between their properties and traces the relationships between properties and entities in depth.
Can I optimize my site for Knowledge Graph and how does Google use it?
The answer here will be short and it is- no, you can’t unless you know the rules of semantic SEO. There are different optimization tactics, but they are just the basis. You need to know Google’s semantics in depth and know exactly where to look in order to benefit from it.
There are no officially announced tactics for properly optimizing Knowledge Graph and related entities, except for adding a structural date, of course, registering on sites from which Google aggregates information.
In fact, Google is already using not only certain sites to retrieve information, but multiple based on quality factors. Keep in mind that Google believes that many sites are useful as knowledge bases that go beyond Wikipedia and Wikidata. It can view sources like IMDB and Yahoo Finance as useful information about facts and entities and retrieve information from them according to the search phrase.
Providing search results based on sorted properties
Inventors: Yiming Li, and Zhenyu Gu
Assignee: Google LLC
United States Patent 9,875,320
Granted: January 23, 2018
Filed: February 8, 2016





